 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIR: Retrieval-Augmented Image Captioning with Comprehensive Understanding
Paper and Code
Dec 02, 2024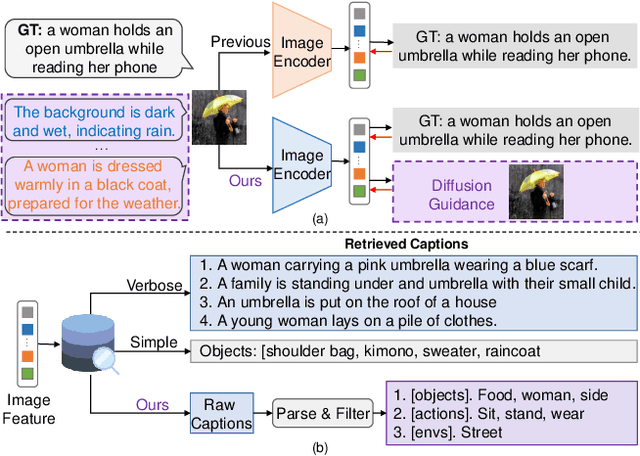
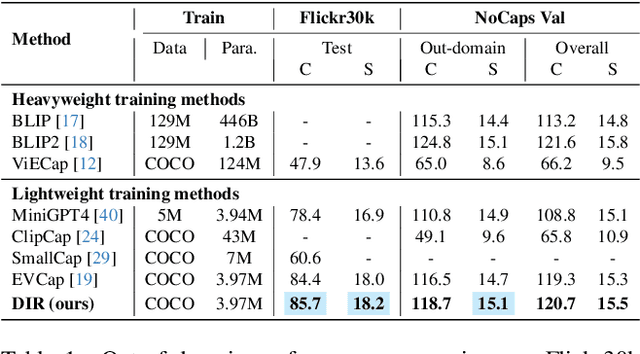
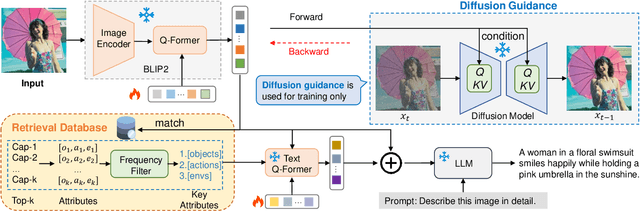
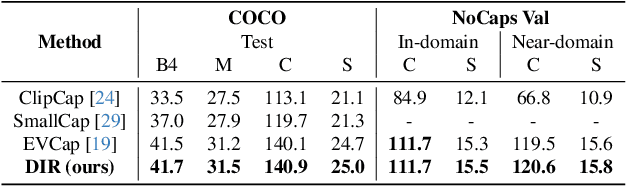
Image captioning models often suffer from performance degradation when applied to novel datasets, as they are typically trained on domain-specific data. To enhance generalization in out-of-domain scenarios, retrieval-augmented approaches have garnered increasing attention. However, current methods face two key challenges: (1) image features used for retrieval are often optimized based on ground-truth (GT) captions, which represent the image from a specific perspective and are influenced by annotator biases, and (2) they underutilize the full potential of retrieved text, typically relying on raw captions or parsed objects, which fail to capture the full semantic richness of the data. In this paper, we propose Dive Into Retrieval (DIR), a method designed to enhance both the image-to-text retrieval process and the utilization of retrieved text to achieve a more comprehensive understanding of the visual content. Our approach introduces two key innovations: (1) diffusion-guided retrieval enhancement, where a pretrained diffusion model guides image feature learning by reconstructing noisy images, allowing the model to capture more comprehensive and fine-grained visual information beyond standard annotated captions; and (2) a high-quality retrieval database, which provides comprehensive semantic information to enhance caption generation, especially in out-of-domain scenarios. Extensive experiments demonstrate that DIR not only maintains competitive in-domain performance but also significantly improves out-of-domain generalization, all without increasing inference costs.