 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Temporal Difference Learning
Paper and Code
Dec 28, 2018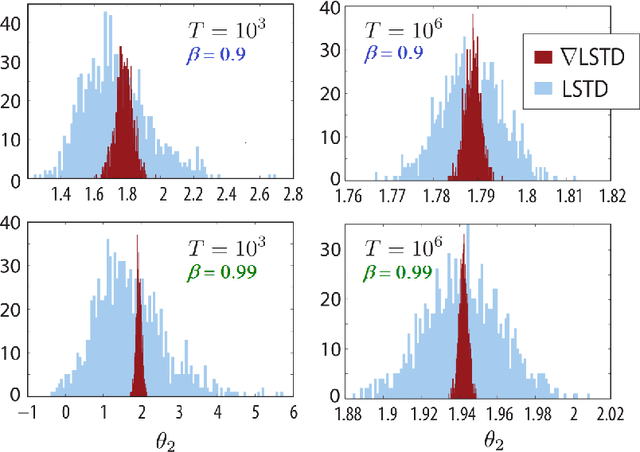
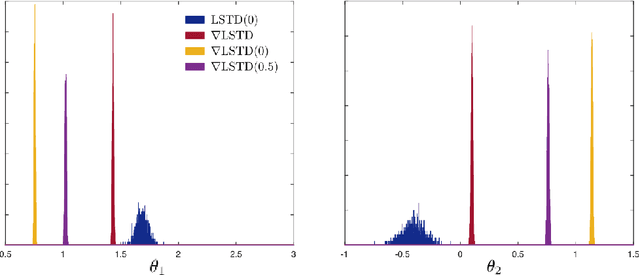
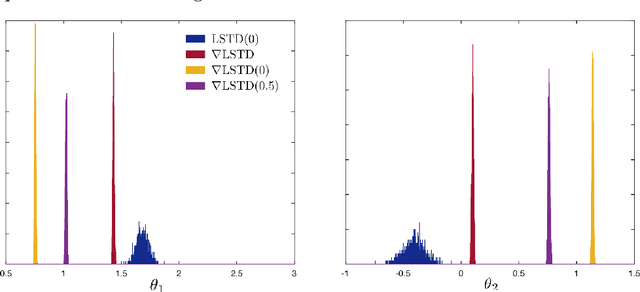
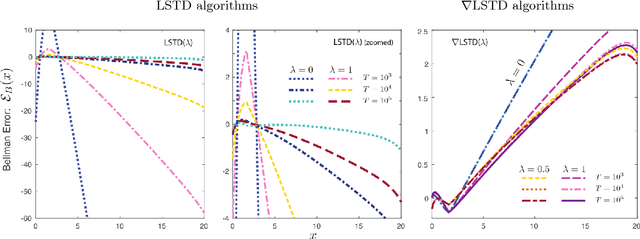
Value functions derived from Markov decision processes arise as a central component of algorithms as well as performance metrics in many statistics and engineering applications of machine learning techniques. Computation of the solution to the associated Bellman equations is challenging in most practical cases of interest. A popular class of approximation techniques, known as Temporal Difference (TD) learning algorithms, are an important sub-class of general reinforcement learning methods. The algorithms introduced in this paper are intended to resolve two well-known difficulties of TD-learning approaches: Their slow convergence due to very high variance, and the fact that, for the problem of computing the relative value function, consistent algorithms exist only in special cases. First we show that the gradients of these value functions admit a representation that lends itself to algorithm design. Based on this result, a new class of differential TD-learning algorithms is introduced. For Markovian models on Euclidean space with smooth dynamics, the algorithms are shown to be consistent under general conditions. Numerical results show dramatic variance reduction when compared to standard methods.