 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDictionary Learning for Robotic Grasp Recognition and Detection
Paper and Code
Jun 02, 2016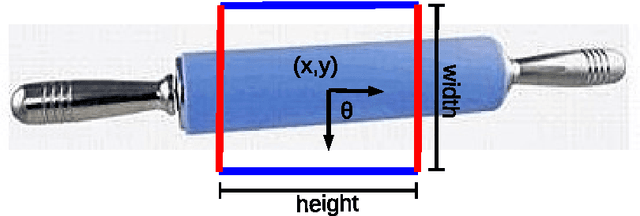


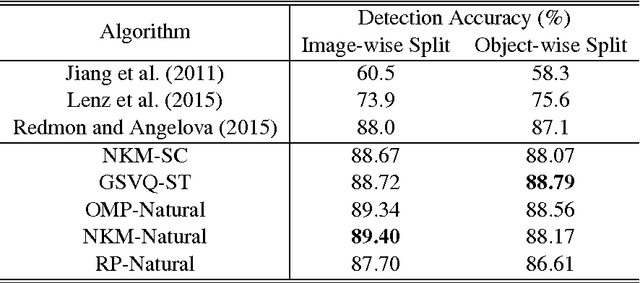
The ability to grasp ordinary and potentially never-seen objects is an important feature in both domestic and industrial robotics. For a system to accomplish this, it must autonomously identify grasping locations by using information from various sensors, such as Microsoft Kinect 3D camera. Despite numerous progress, significant work still remains to be done in this field. To this effect, we propose a dictionary learning and sparse representation (DLSR) framework for representing RGBD images from 3D sensors in the context of determining such good grasping locations. In contrast to previously proposed approaches that relied on sophisticated regularization or very large datasets, the derived perception system has a fast training phase and can work with small datasets. It is also theoretically founded for dealing with masked-out entries, which are common with 3D sensors. We contribute by presenting a comparative study of several DLSR approach combinations for recognizing and detecting grasp candidates on the standard Cornell dataset. Importantly, experimental results show a performance improvement of 1.69% in detection and 3.16% in recognition over current state-of-the-art convolutional neural network (CNN). Even though nowadays most popular vision-based approach is CNN, this suggests that DLSR is also a viable alternative with interesting advantages that CNN has not.