 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Motion Code Embedding for Action Recognition in Videos
Paper and Code
Dec 10, 2020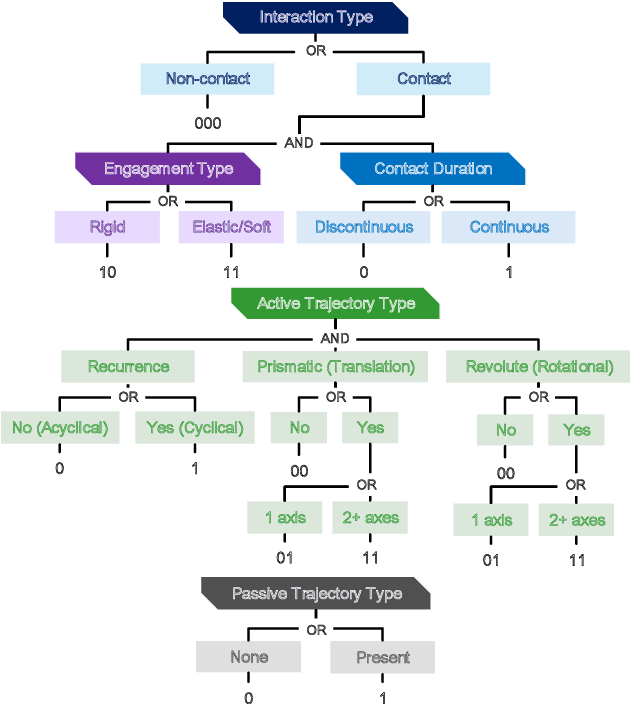
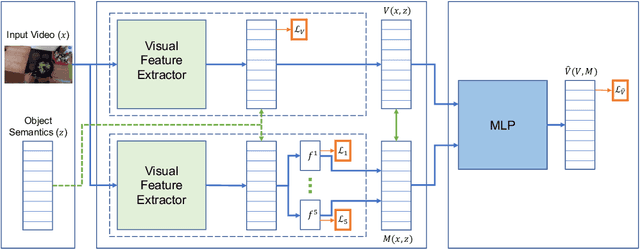


In this work, we propose a motion embedding strategy known as motion codes, which is a vectorized representation of motions based on a manipulation's salient mechanical attributes. These motion codes provide a robust motion representation, and they are obtained using a hierarchy of features called the motion taxonomy. We developed and trained a deep neural network model that combines visual and semantic features to identify the features found in our motion taxonomy to embed or annotate videos with motion codes. To demonstrate the potential of motion codes as features for machine learning tasks, we integrated the extracted features from the motion embedding model into the current state-of-the-art action recognition model. The obtained model achieved higher accuracy than the baseline model for the verb classification task on egocentric videos from the EPIC-KITCHENS dataset.