 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection and Localization of Robotic Tools in Robot-Assisted Surgery Videos Using Deep Neural Networks for Region Proposal and Detection
Paper and Code
Jul 29, 2020
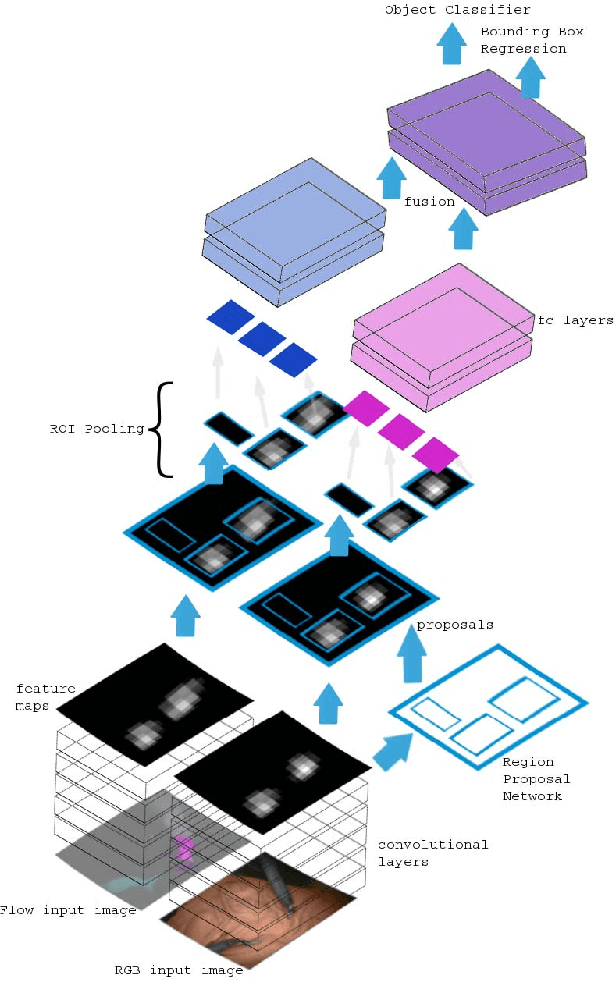
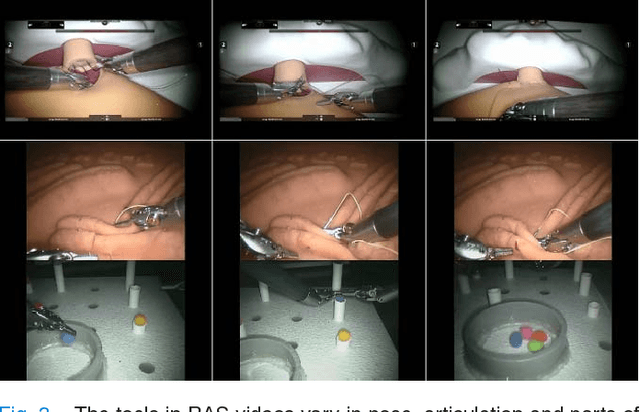

Video understanding of robot-assisted surgery (RAS) videos is an active research area. Modeling the gestures and skill level of surgeons presents an interesting problem. The insights drawn may be applied in effective skill acquisition, objective skill assessment, real-time feedback, and human-robot collaborative surgeries. We propose a solution to the tool detection and localization open problem in RAS video understanding, using a strictly computer vision approach and the recent advances of deep learning. We propose an architecture using multimodal convolutional neural networks for fast detection and localization of tools in RAS videos. To our knowledge, this approach will be the first to incorporate deep neural networks for tool detection and localization in RAS videos. Our architecture applies a Region Proposal Network (RPN), and a multi-modal two stream convolutional network for object detection, to jointly predict objectness and localization on a fusion of image and temporal motion cues. Our results with an Average Precision (AP) of 91% and a mean computation time of 0.1 seconds per test frame detection indicate that our study is superior to conventionally used methods for medical imaging while also emphasizing the benefits of using RPN for precision and efficiency. We also introduce a new dataset, ATLAS Dione, for RAS video understanding. Our dataset provides video data of ten surgeons from Roswell Park Cancer Institute (RPCI) (Buffalo, NY) performing six different surgical tasks on the daVinci Surgical System (dVSS R ) with annotations of robotic tools per frame.