 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDessiLBI: Exploring Structural Sparsity of Deep Networks via Differential Inclusion Paths
Paper and Code

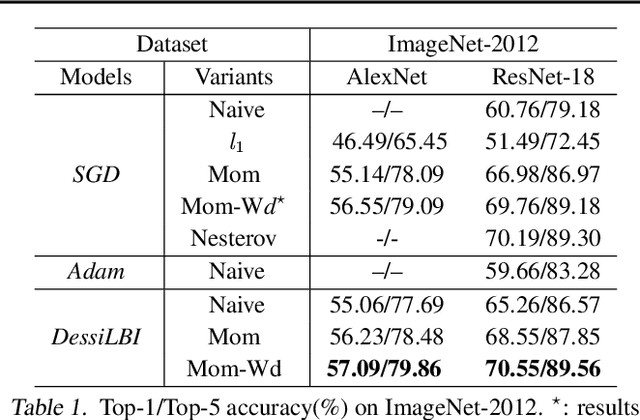
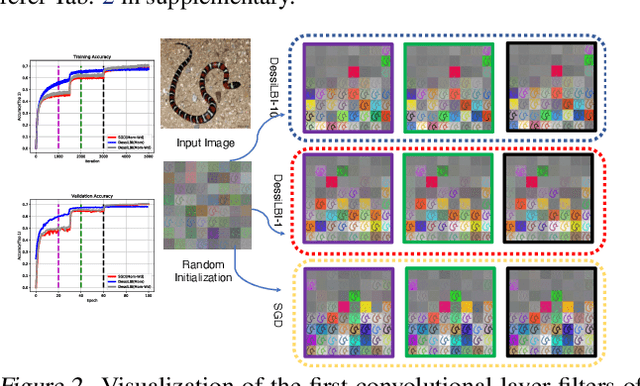

Over-parameterization is ubiquitous nowadays in training neural networks to benefit both optimization in seeking global optima and generalization in reducing prediction error. However, compressive networks are desired in many real world applications and direct training of small networks may be trapped in local optima. In this paper, instead of pruning or distilling over-parameterized models to compressive ones, we propose a new approach based on differential inclusions of inverse scale spaces. Specifically, it generates a family of models from simple to complex ones that couples a pair of parameters to simultaneously train over-parameterized deep models and structural sparsity on weights of fully connected and convolutional layers. Such a differential inclusion scheme has a simple discretization, proposed as Deep structurally splitting Linearized Bregman Iteration (DessiLBI), whose global convergence analysis in deep learning is established that from any initializations, algorithmic iterations converge to a critical point of empirical risks. Experimental evidence shows that DessiLBI achieve comparable and even better performance than the competitive optimizers in exploring the structural sparsity of several widely used backbones on the benchmark datasets. Remarkably, with early stopping, DessiLBI unveils "winning tickets" in early epochs: the effective sparse structure with comparable test accuracy to fully trained over-parameterized models.