 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Analysis of Uplink and Downlink Communications for Federated Learning
Paper and Code
Dec 07, 2020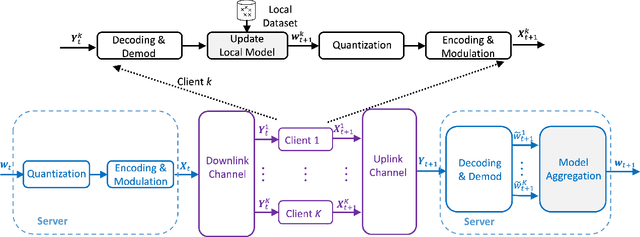
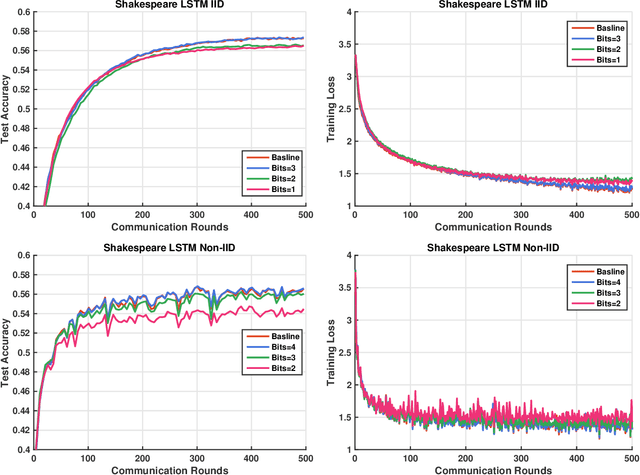
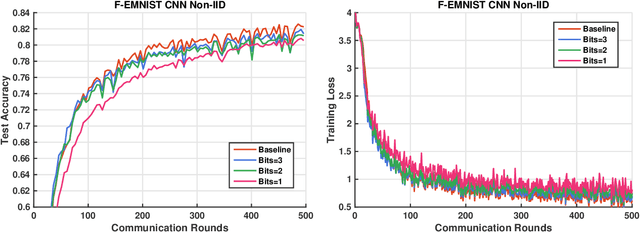
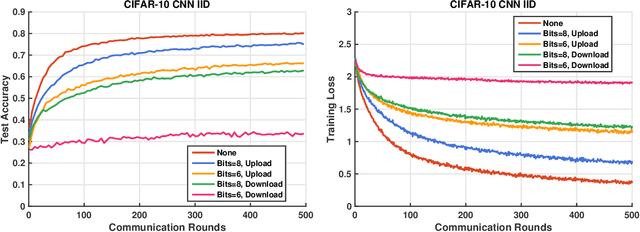
Communication has been known to be one of the primary bottlenecks of federated learning (FL), and yet existing studies have not addressed the efficient communication design, particularly in wireless FL where both uplink and downlink communications have to be considered. In this paper, we focus on the design and analysis of physical layer quantization and transmission methods for wireless FL. We answer the question of what and how to communicate between clients and the parameter server and evaluate the impact of the various quantization and transmission options of the updated model on the learning performance. We provide new convergence analysis of the well-known FedAvg under non-i.i.d. dataset distributions, partial clients participation, and finite-precision quantization in uplink and downlink communications. These analyses reveal that, in order to achieve an O(1/T) convergence rate with quantization, transmitting the weight requires increasing the quantization level at a logarithmic rate, while transmitting the weight differential can keep a constant quantization level. Comprehensive numerical evaluation on various real-world datasets reveals that the benefit of a FL-tailored uplink and downlink communication design is enormous - a carefully designed quantization and transmission achieves more than 98% of the floating-point baseline accuracy with fewer than 10% of the baseline bandwidth, for majority of the experiments on both i.i.d. and non-i.i.d. datasets. In particular, 1-bit quantization (3.1% of the floating-point baseline bandwidth) achieves 99.8% of the floating-point baseline accuracy at almost the same convergence rate on MNIST, representing the best known bandwidth-accuracy tradeoff to the best of the authors' knowledge.