 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense and Sparse Coding: Theory and Architectures
Paper and Code

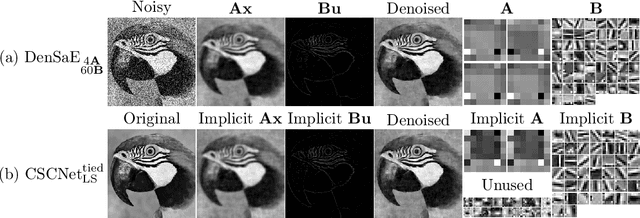
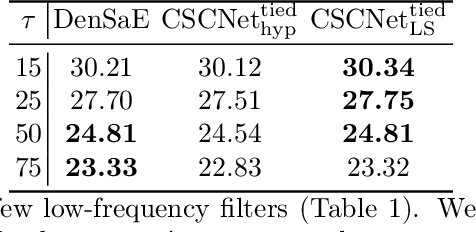
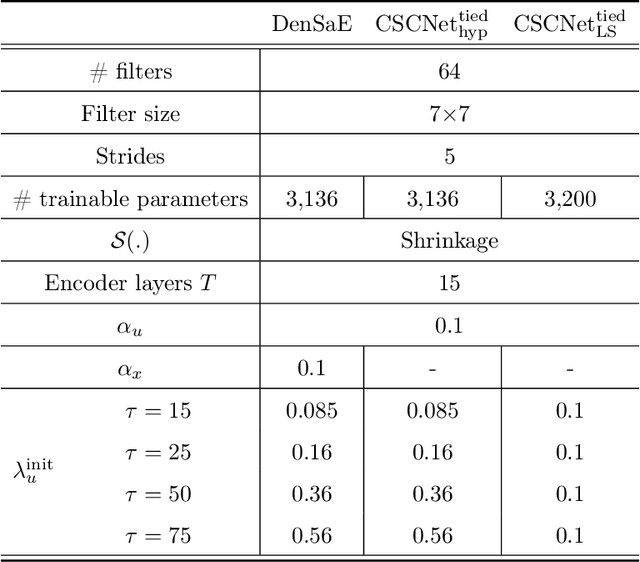
The sparse representation model has been successfully utilized in a number of signal and image processing tasks; however, recent research has highlighted its limitations in certain deep-learning architectures. This paper proposes a novel dense and sparse coding model that considers the problem of recovering a dense vector $\mathbf{x}$ and a sparse vector $\mathbf{u}$ given linear measurements of the form $\mathbf{y} = \mathbf{A}\mathbf{x}+\mathbf{B}\mathbf{u}$. Our first theoretical result proposes a new natural geometric condition based on the minimal angle between subspaces corresponding to the measurement matrices $\mathbf{A}$ and $\mathbf{B}$ to establish the uniqueness of solutions to the linear system. The second analysis shows that, under mild assumptions and sufficient linear measurements, a convex program recovers the dense and sparse components with high probability. The standard RIPless analysis cannot be directly applied to this setup. Our proof is a non-trivial adaptation of techniques from anisotropic compressive sensing theory and is based on an analysis of a matrix derived from the measurement matrices $\mathbf{A}$ and $\mathbf{B}$. We begin by demonstrating the effectiveness of the proposed model on simulated data. Then, to address its use in a dictionary learning setting, we propose a dense and sparse auto-encoder (DenSaE) that is tailored to it. We demonstrate that a) DenSaE denoises natural images better than architectures derived from the sparse coding model ($\mathbf{B}\mathbf{u}$), b) training the biases in the latter amounts to implicitly learning the $\mathbf{A}\mathbf{x} + \mathbf{B}\mathbf{u}$ model, and c) $\mathbf{A}$ and $\mathbf{B}$ capture low- and high-frequency contents, respectively.