 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Backdoor Attacks on Vision Transformer via Patch Processing
Paper and Code
Jun 24, 2022


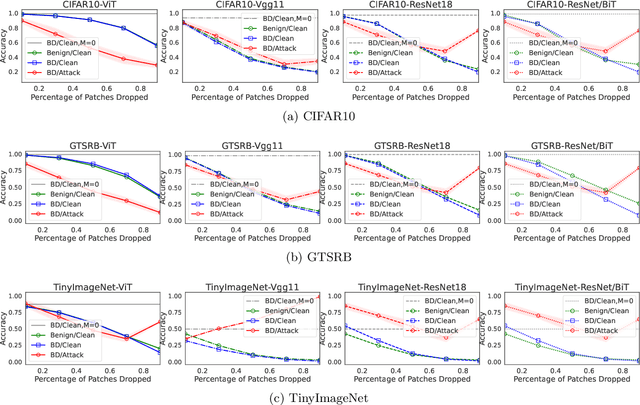
Vision Transformers (ViTs) have a radically different architecture with significantly less inductive bias than Convolutional Neural Networks. Along with the improvement in performance, security and robustness of ViTs are also of great importance to study. In contrast to many recent works that exploit the robustness of ViTs against adversarial examples, this paper investigates a representative causative attack, i.e., backdoor. We first examine the vulnerability of ViTs against various backdoor attacks and find that ViTs are also quite vulnerable to existing attacks. However, we observe that the clean-data accuracy and backdoor attack success rate of ViTs respond distinctively to patch transformations before the positional encoding. Then, based on this finding, we propose an effective method for ViTs to defend both patch-based and blending-based trigger backdoor attacks via patch processing. The performances are evaluated on several benchmark datasets, including CIFAR10, GTSRB, and TinyImageNet, which show the proposed novel defense is very successful in mitigating backdoor attacks for ViTs. To the best of our knowledge, this paper presents the first defensive strategy that utilizes a unique characteristic of ViTs against backdoor attacks.