 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeply Aligned Adaptation for Cross-domain Object Detection
Paper and Code
Apr 09, 2020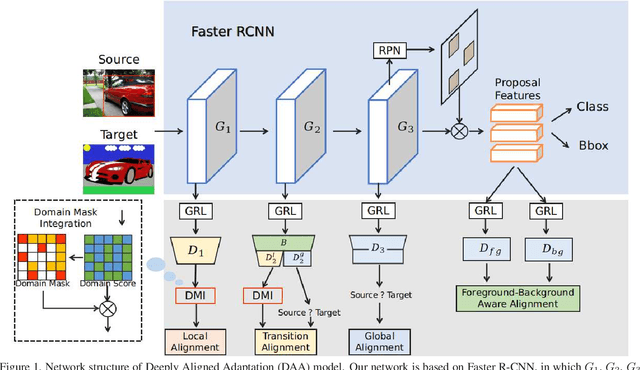
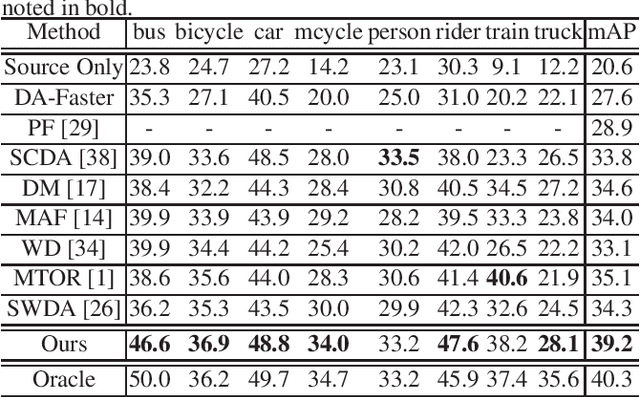
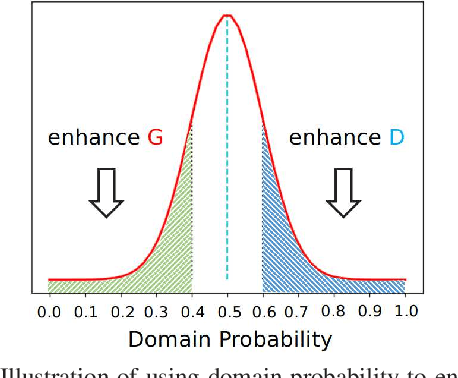
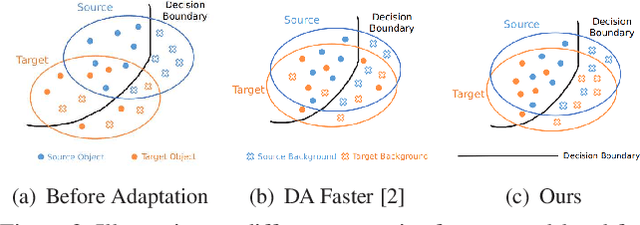
Cross-domain object detection has recently attracted more and more attention for real-world applications, since it helps build robust detectors adapting well to new environments. In this work, we propose an end-to-end solution based on Faster R-CNN, where ground-truth annotations are available for source images (e.g., cartoon) but not for target ones (e.g., watercolor) during training. Motivated by the observation that the transferabilities of different neural network layers differ from each other, we propose to apply a number of domain alignment strategies to different layers of Faster R-CNN, where the alignment strength is gradually reduced from low to higher layers. Moreover, after obtaining region proposals in our network, we develop a foreground-background aware alignment module to further reduce the domain mismatch by separately aligning features of the foreground and background regions from the source and target domains. Extensive experiments on benchmark datasets demonstrate the effectiveness of our proposed approach.