 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEEPEYE: A Compact and Accurate Video Comprehension at Terminal Devices Compressed with Quantization and Tensorization
Paper and Code
Jun 07, 2018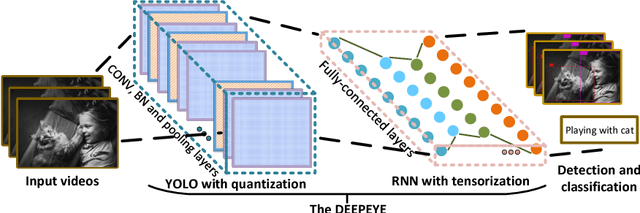
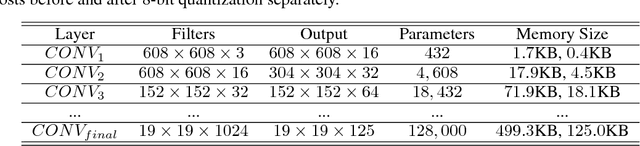
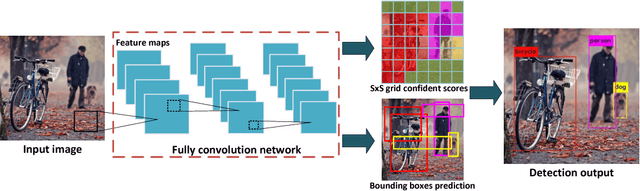

As it requires a huge number of parameters when exposed to high dimensional inputs in video detection and classification, there is a grand challenge to develop a compact yet accurate video comprehension at terminal devices. Current works focus on optimizations of video detection and classification in a separated fashion. In this paper, we introduce a video comprehension (object detection and action recognition) system for terminal devices, namely DEEPEYE. Based on You Only Look Once (YOLO), we have developed an 8-bit quantization method when training YOLO; and also developed a tensorized-compression method of Recurrent Neural Network (RNN) composed of features extracted from YOLO. The developed quantization and tensorization can significantly compress the original network model yet with maintained accuracy. Using the challenging video datasets: MOMENTS and UCF11 as benchmarks, the results show that the proposed DEEPEYE achieves 3.994x model compression rate with only 0.47% mAP decreased; and 15,047x parameter reduction and 2.87x speed-up with 16.58% accuracy improvement.