 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeper Insights into ViTs Robustness towards Common Corruptions
Paper and Code
Apr 29, 2022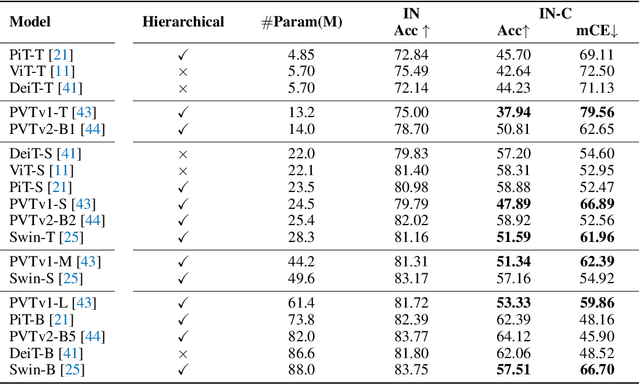



Recent literature have shown design strategies from Convolutions Neural Networks (CNNs) benefit Vision Transformers (ViTs) in various vision tasks. However, it remains unclear how these design choices impact on robustness when transferred to ViTs. In this paper, we make the first attempt to investigate how CNN-like architectural designs and CNN-based data augmentation strategies impact on ViTs' robustness towards common corruptions through an extensive and rigorous benchmarking. We demonstrate that overlapping patch embedding and convolutional Feed-Forward Network (FFN) boost performance on robustness. Furthermore, adversarial noise training is powerful on ViTs while fourier-domain augmentation fails. Moreover, we introduce a novel conditional method enabling input-varied augmentations from two angles: (1) Generating dynamic augmentation parameters conditioned on input images. It conduces to state-of-the-art performance on robustness through conditional convolutions; (2) Selecting most suitable augmentation strategy by an extra predictor helps to achieve the best trade-off between clean accuracy and robustness.