 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Variational Generative Models for Audio-visual Speech Separation
Paper and Code
Aug 17, 2020

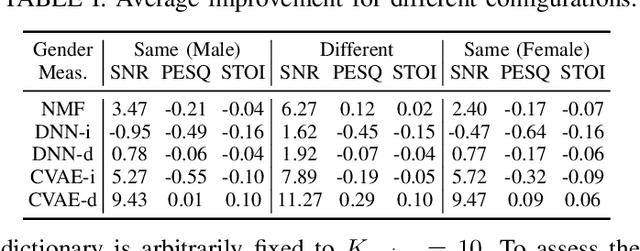
In this paper, we are interested in audio-visual speech separation given a single-channel audio recording as well as visual information (lips movements) associated with each speaker. We propose an unsupervised technique based on audio-visual generative modeling of clean speech. More specifically, during training, a latent variable generative model is learned from clean speech spectrograms using a variational auto-encoder (VAE). To better utilize the visual information, the posteriors of the latent variables are inferred from mixed speech (instead of clean speech) as well as the visual data. The visual modality also serves as a prior for latent variables, through a visual network. At test time, the learned generative model (both for speaker-independent and speaker-dependent scenarios) is combined with an unsupervised non-negative matrix factorization (NMF) variance model for background noise. All the latent variables and noise parameters are then estimated by a Monte Carlo expectation-maximization algorithm. Our experiments show that the proposed unsupervised VAE-based method yields better separation performance than NMF-based approaches as well as a supervised deep learning-based technique.