Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Probabilistic Ensembles: Approximate Variational Inference through KL Regularization
Paper and Code
Nov 30, 2018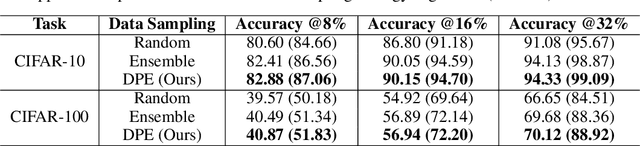

In this paper, we introduce Deep Probabilistic Ensembles (DPEs), a scalable technique that uses a regularized ensemble to approximate a deep Bayesian Neural Network (BNN). We do so by incorporating a KL divergence penalty term into the training objective of an ensemble, derived from the evidence lower bound used in variational inference. We evaluate the uncertainty estimates obtained from our models for active learning on visual classification. Our approach steadily improves upon active learning baselines as the annotation budget is increased.
* Workshop on Bayesian Deep Learning (NeurIPS 2018)
View paper on