 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Network Fingerprinting by Conferrable Adversarial Examples
Paper and Code
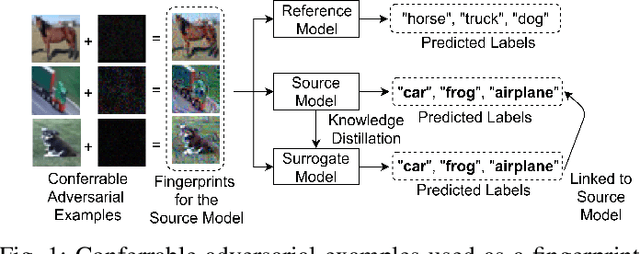


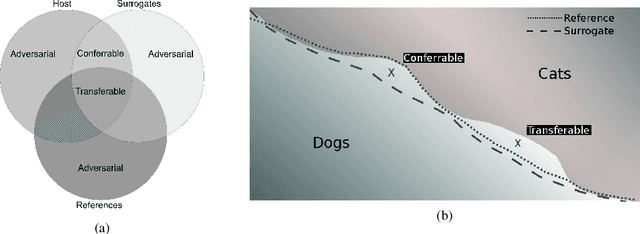
In Machine Learning as a Service, a provider trains a deep neural network and provides many users access to it. However, the hosted (source) model is susceptible to model stealing attacks where an adversary derives a \emph{surrogate model} from API access to the source model. For post hoc detection of such attacks, the provider needs a robust method to determine whether a suspect model is a surrogate of their model or not. We propose a fingerprinting method for deep neural networks that extracts a set of inputs from the source model so that only surrogates agree with the source model on the classification of such inputs. These inputs are a specifically crafted subclass of targeted transferable adversarial examples which we call conferrable adversarial examples that transfer exclusively from a source model to its surrogates. We propose new methods to generate these conferrable adversarial examples and use them as our fingerprint. Our fingerprint is the first to be successfully tested as robust against distillation attacks, and our experiments show that this robustness extends to robustness against weaker removal attacks such as fine-tuning, ensemble attacks, and adversarial retraining. We even protect against a powerful adversary with white-box access to the source model, whereas the defender only needs black-box access to the surrogate model. We conduct our experiments on the CINIC dataset and a subset of ImageNet32 with 100 classes.