 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Networks and the Multiple Manifold Problem
Paper and Code
Aug 25, 2020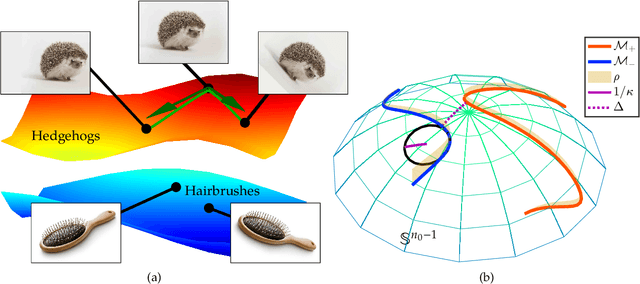
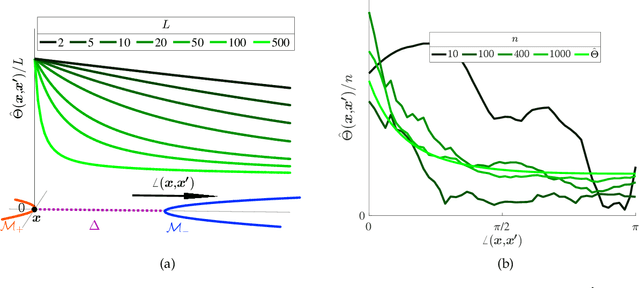
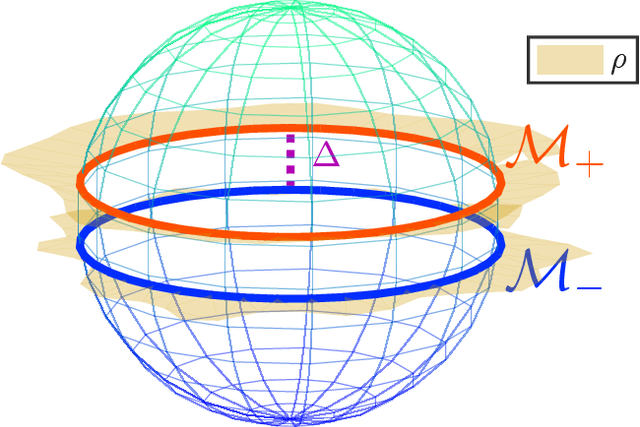
We study the multiple manifold problem, a binary classification task modeled on applications in machine vision, in which a deep fully-connected neural network is trained to separate two low-dimensional submanifolds of the unit sphere. We provide an analysis of the one-dimensional case, proving for a simple manifold configuration that when the network depth $L$ is large relative to certain geometric and statistical properties of the data, the network width $n$ grows as a sufficiently large polynomial in $L$, and the number of i.i.d. samples from the manifolds is polynomial in $L$, randomly-initialized gradient descent rapidly learns to classify the two manifolds perfectly with high probability. Our analysis demonstrates concrete benefits of depth and width in the context of a practically-motivated model problem: the depth acts as a fitting resource, with larger depths corresponding to smoother networks that can more readily separate the class manifolds, and the width acts as a statistical resource, enabling concentration of the randomly-initialized network and its gradients. The argument centers around the neural tangent kernel and its role in the nonasymptotic analysis of training overparameterized neural networks; to this literature, we contribute essentially optimal rates of concentration for the neural tangent kernel of deep fully-connected networks, requiring width $n \gtrsim L\,\mathrm{poly}(d_0)$ to achieve uniform concentration of the initial kernel over a $d_0$-dimensional submanifold of the unit sphere $\mathbb{S}^{n_0-1}$, and a nonasymptotic framework for establishing generalization of networks trained in the NTK regime with structured data. The proof makes heavy use of martingale concentration to optimally treat statistical dependencies across layers of the initial random network. This approach should be of use in establishing similar results for other network architectures.