 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multimodal Neural Architecture Search
Paper and Code
Apr 25, 2020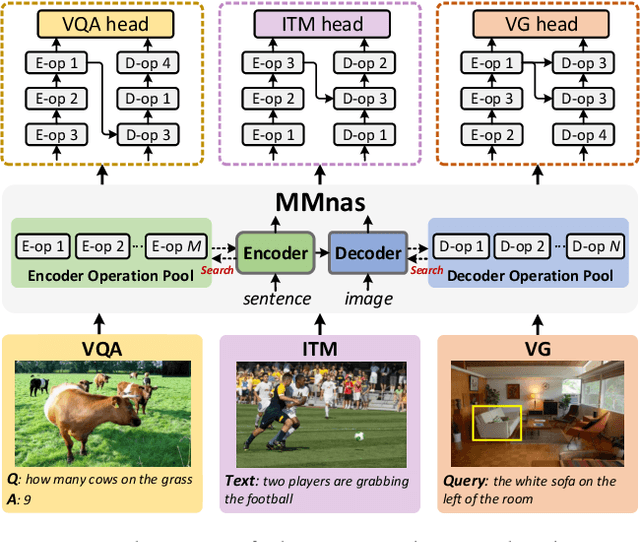
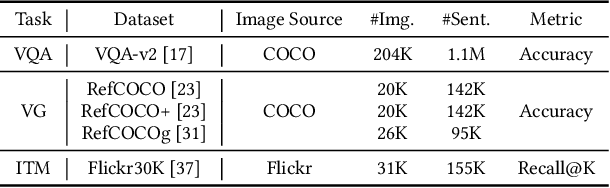
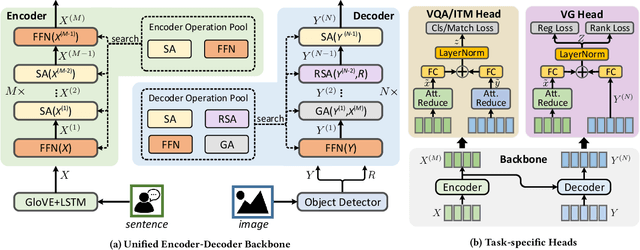
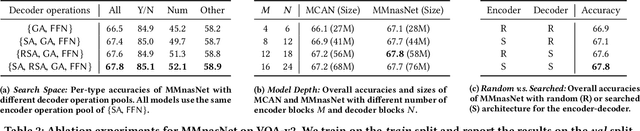
Designing effective neural networks is fundamentally important in deep multimodal learning. Most existing works focus on a single task and design neural architectures manually, which are highly task-specific and hard to generalize to different tasks. In this paper, we devise a generalized deep multimodal neural architecture search (MMnas) framework for various multimodal learning tasks. Given multimodal input, we first define a set of primitive operations, and then construct a deep encoder-decoder based unified backbone, where each encoder or decoder block corresponds to an operation searched from a predefined operation pool. On top of the unified backbone, we attach task-specific heads to tackle different multimodal learning tasks. By using a gradient-based NAS algorithm, the optimal architectures for different tasks are learned efficiently. Extensive ablation studies, comprehensive analysis, and superior experimental results show that MMnasNet significantly outperforms existing state-of-the-art approaches across three multimodal learning tasks (over five datasets), including visual question answering, image-text matching, and visual grounding. Code will be made available.