 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Models for Knowledge Tracing: Review and Empirical Evaluation
Paper and Code
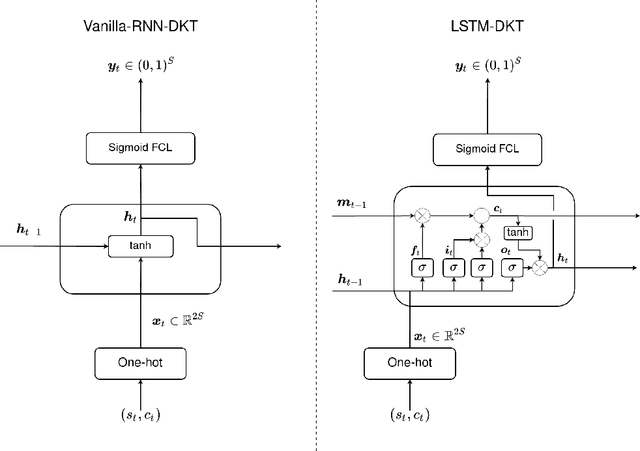

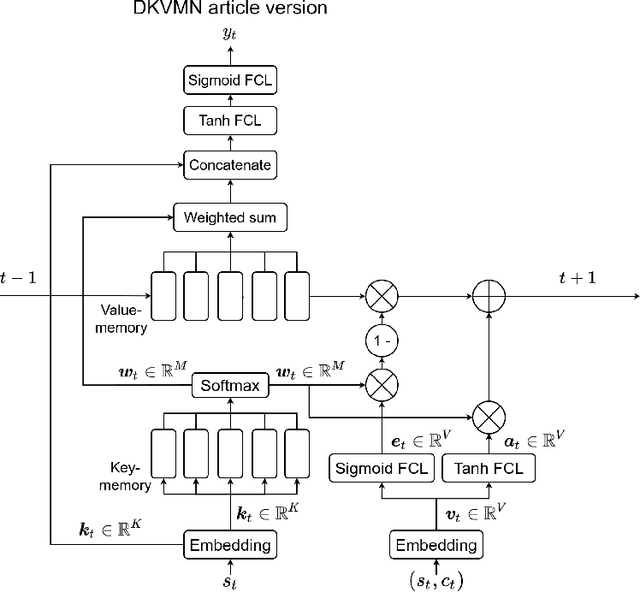
In this work, we review and evaluate a body of deep learning knowledge tracing (DLKT) models with openly available and widely-used data sets, and with a novel data set of students learning to program. The evaluated DLKT models have been reimplemented for assessing reproducibility and replicability of previously reported results. We test different input and output layer variations found in the compared models that are independent of the main architectures of the models, and different maximum attempt count options that have been implicitly and explicitly used in some studies. Several metrics are used to reflect on the quality of the evaluated knowledge tracing models. The evaluated knowledge tracing models include Vanilla-DKT, two Long Short-Term Memory Deep Knowledge Tracing (LSTM-DKT) variants, two Dynamic Key-Value Memory Network (DKVMN) variants, and Self-Attentive Knowledge Tracing (SAKT). We evaluate logistic regression, Bayesian Knowledge Tracing (BKT) and simple non-learning models as baselines. Our results suggest that the DLKT models in general outperform non-DLKT models, and the relative differences between the DLKT models are subtle and often vary between datasets. Our results also show that naive models such as mean prediction can yield better performance than more sophisticated knowledge tracing models, especially in terms of accuracy. Further, our metric and hyperparameter analysis shows that the metric used to select the best model hyperparameters has a noticeable effect on the performance of the models, and that metric choice can affect model ranking. We also study the impact of input and output layer variations, filtering out long attempt sequences, and non-model properties such as randomness and hardware. Finally, we discuss model performance replicability and related issues. Our model implementations, evaluation code, and data are published as a part of this work.