 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Layer-wise Networks Have Closed-Form Weights
Paper and Code
Feb 07, 2022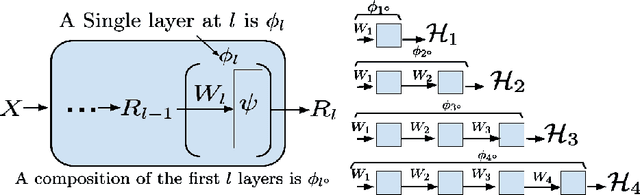
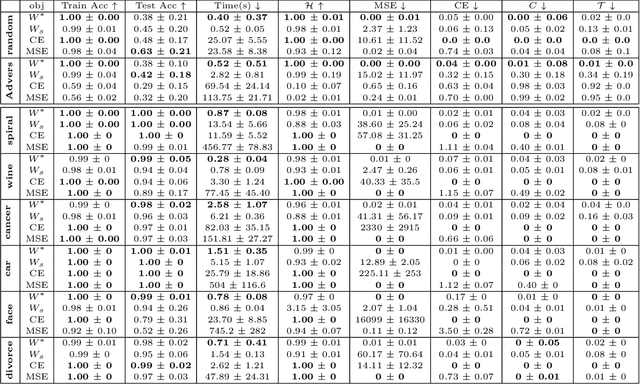
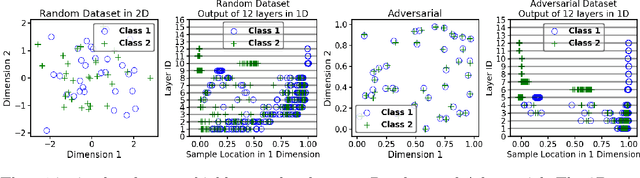
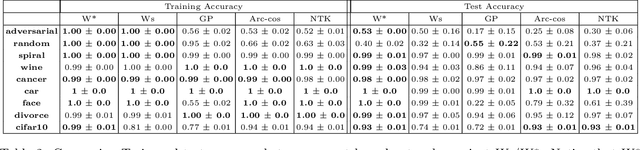
There is currently a debate within the neuroscience community over the likelihood of the brain performing backpropagation (BP). To better mimic the brain, training a network \textit{one layer at a time} with only a "single forward pass" has been proposed as an alternative to bypass BP; we refer to these networks as "layer-wise" networks. We continue the work on layer-wise networks by answering two outstanding questions. First, $\textit{do they have a closed-form solution?}$ Second, $\textit{how do we know when to stop adding more layers?}$ This work proves that the Kernel Mean Embedding is the closed-form weight that achieves the network global optimum while driving these networks to converge towards a highly desirable kernel for classification; we call it the $\textit{Neural Indicator Kernel}$.