 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Keypoint-Based Camera Pose Estimation with Geometric Constraints
Paper and Code
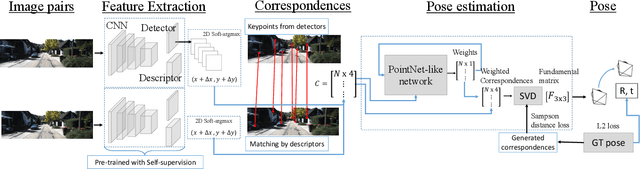
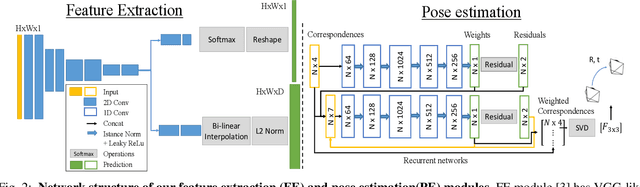


Estimating relative camera poses from consecutive frames is a fundamental problem in visual odometry (VO) and simultaneous localization and mapping (SLAM), where classic methods consisting of hand-crafted features and sampling-based outlier rejection have been a dominant choice for over a decade. Although multiple works propose to replace these modules with learning-based counterparts, most have not yet been as accurate, robust and generalizable as conventional methods. In this paper, we design an end-to-end trainable framework consisting of learnable modules for detection, feature extraction, matching and outlier rejection, while directly optimizing for the geometric pose objective. We show both quantitatively and qualitatively that pose estimation performance may be achieved on par with the classic pipeline. Moreover, we are able to show by end-to-end training, the key components of the pipeline could be significantly improved, which leads to better generalizability to unseen datasets compared to existing learning-based methods.