 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Convolutional Pooling Transformer for Deepfake Detection
Paper and Code
Sep 12, 2022
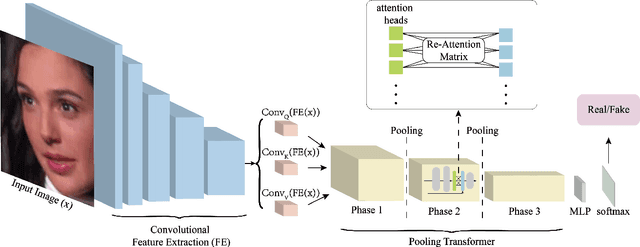
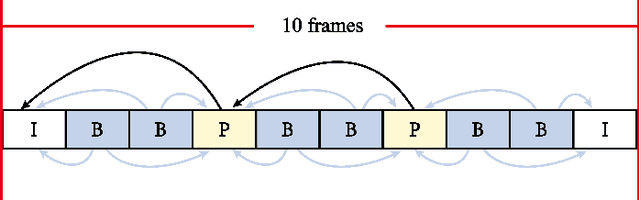
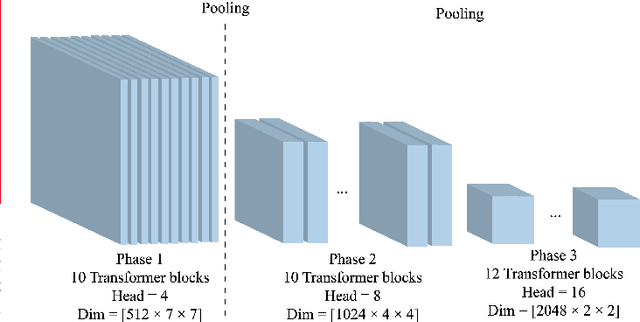
Recently, Deepfake has drawn considerable public attention due to security and privacy concerns in social media digital forensics. As the wildly spreading Deepfake videos on the Internet become more realistic, traditional detection techniques have failed in distinguishing between the real and fake. Most existing deep learning methods mainly focus on local features and relations within the face image using convolutional neural networks as a backbone. However, local features and relations are insufficient for model training to learn enough general information for Deepfake detection. Therefore, the existing Deepfake detection methods have reached a bottleneck to further improving the detection performance. To address this issue, we propose a deep convolutional Transformer to incorporate the decisive image features both locally and globally. Specifically, we apply convolutional pooling and re-attention to enrich the extracted features and enhance the efficacy. Moreover, we employ the barely discussed image keyframes in model training for performance improvement and visualize the feature quantity gap between the key and normal image frames caused by video compression. We finally illustrate the transferability with extensive experiments on several Deepfake benchmark datasets. The proposed solution consistently outperforms several state-of-the-art baselines on both within- and cross-dataset experiments.