 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Visual-Semantic Feature Learning for Robust Scene Text Recognition
Paper and Code
Nov 24, 2021
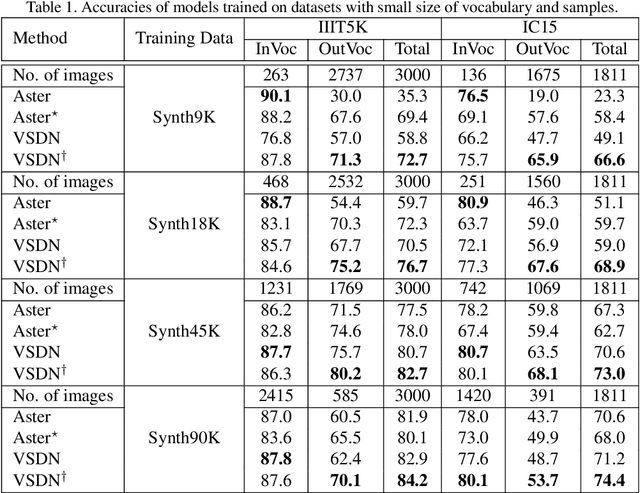
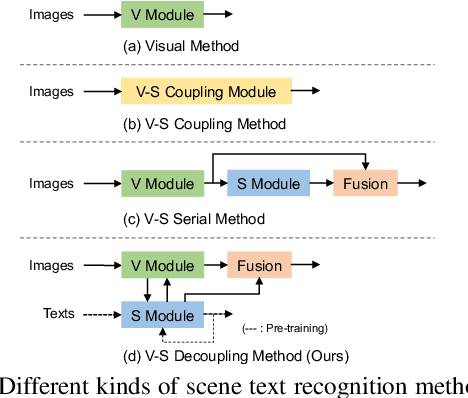
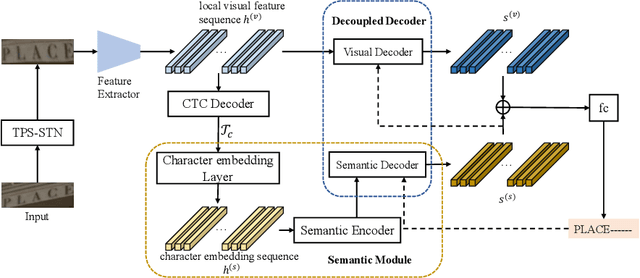
Semantic information has been proved effective in scene text recognition. Most existing methods tend to couple both visual and semantic information in an attention-based decoder. As a result, the learning of semantic features is prone to have a bias on the limited vocabulary of the training set, which is called vocabulary reliance. In this paper, we propose a novel Visual-Semantic Decoupling Network (VSDN) to address the problem. Our VSDN contains a Visual Decoder (VD) and a Semantic Decoder (SD) to learn purer visual and semantic feature representation respectively. Besides, a Semantic Encoder (SE) is designed to match SD, which can be pre-trained together by additional inexpensive large vocabulary via a simple word correction task. Thus the semantic feature is more unbiased and precise to guide the visual feature alignment and enrich the final character representation. Experiments show that our method achieves state-of-the-art or competitive results on the standard benchmarks, and outperforms the popular baseline by a large margin under circumstances where the training set has a small size of vocabulary.