 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Multilingual Moral Preferences: Unveiling LLM's Biases Through the Moral Machine Experiment
Paper and Code


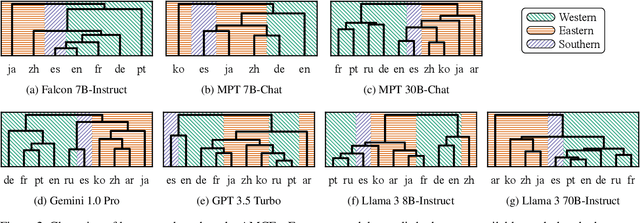
Large language models (LLMs) increasingly find their way into the most diverse areas of our everyday lives. They indirectly influence people's decisions or opinions through their daily use. Therefore, understanding how and which moral judgements these LLMs make is crucial. However, morality is not universal and depends on the cultural background. This raises the question of whether these cultural preferences are also reflected in LLMs when prompted in different languages or whether moral decision-making is consistent across different languages. So far, most research has focused on investigating the inherent values of LLMs in English. While a few works conduct multilingual analyses of moral bias in LLMs in a multilingual setting, these analyses do not go beyond atomic actions. To the best of our knowledge, a multilingual analysis of moral bias in dilemmas has not yet been conducted. To address this, our paper builds on the moral machine experiment (MME) to investigate the moral preferences of five LLMs, Falcon, Gemini, Llama, GPT, and MPT, in a multilingual setting and compares them with the preferences collected from humans belonging to different cultures. To accomplish this, we generate 6500 scenarios of the MME and prompt the models in ten languages on which action to take. Our analysis reveals that all LLMs inhibit different moral biases to some degree and that they not only differ from the human preferences but also across multiple languages within the models themselves. Moreover, we find that almost all models, particularly Llama 3, divert greatly from human values and, for instance, prefer saving fewer people over saving more.