 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Focused Evaluation of Worst-Case Distribution Shift
Paper and Code
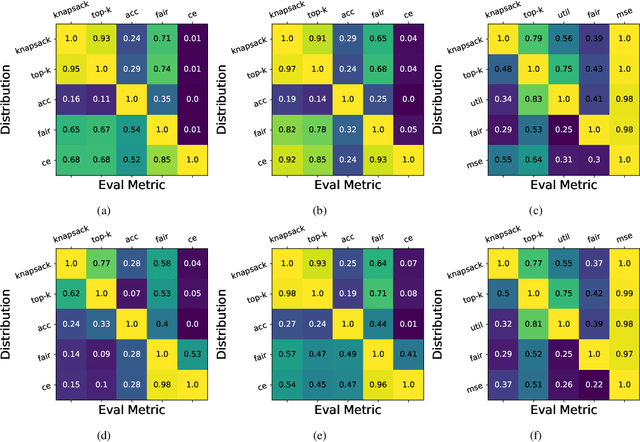
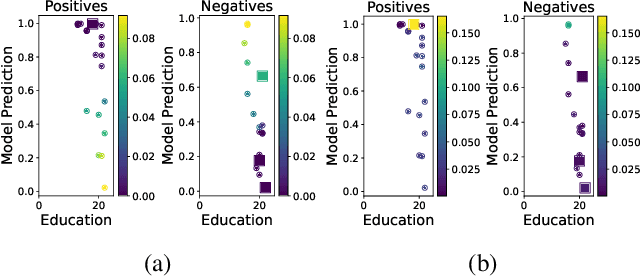
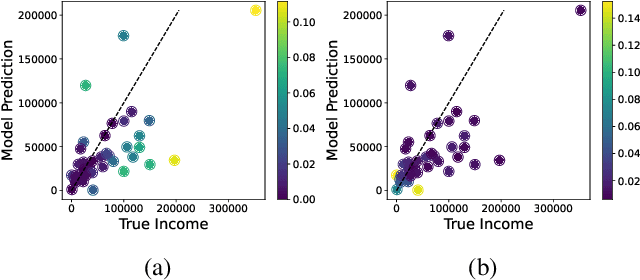
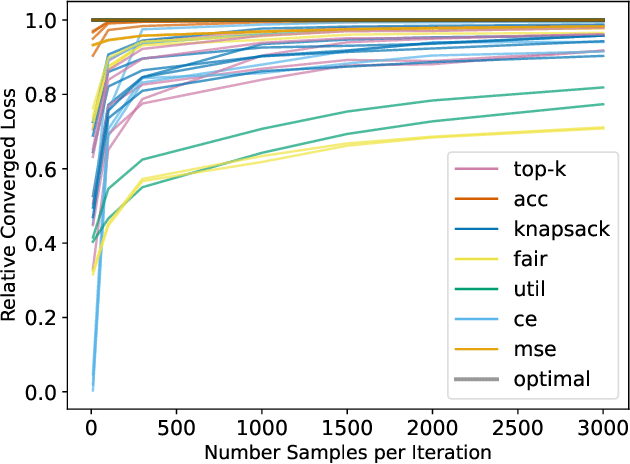
Distribution shift is a key challenge for predictive models in practice, creating the need to identify potentially harmful shifts in advance of deployment. Existing work typically defines these worst-case shifts as ones that most degrade the individual-level accuracy of the model. However, when models are used to make a downstream population-level decision like the allocation of a scarce resource, individual-level accuracy may be a poor proxy for performance on the task at hand. We introduce a novel framework that employs a hierarchical model structure to identify worst-case distribution shifts in predictive resource allocation settings by capturing shifts both within and across instances of the decision problem. This task is more difficult than in standard distribution shift settings due to combinatorial interactions, where decisions depend on the joint presence of individuals in the allocation task. We show that the problem can be reformulated as a submodular optimization problem, enabling efficient approximations of worst-case loss. Applying our framework to real data, we find empirical evidence that worst-case shifts identified by one metric often significantly diverge from worst-case distributions identified by other metrics.