 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceptive Sequential Decision-Making via Regularized Policy Optimization
Paper and Code
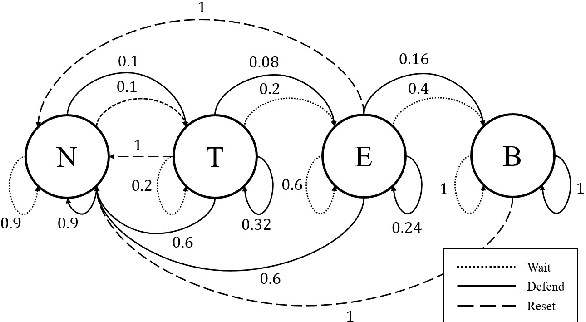

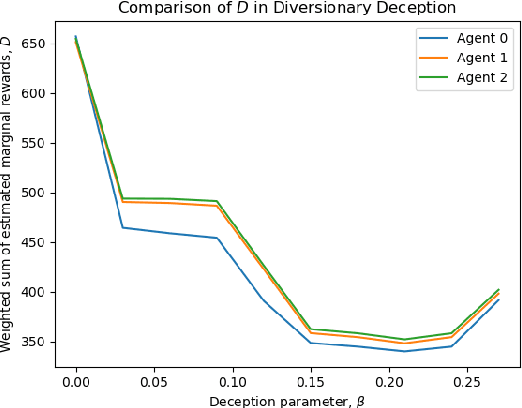
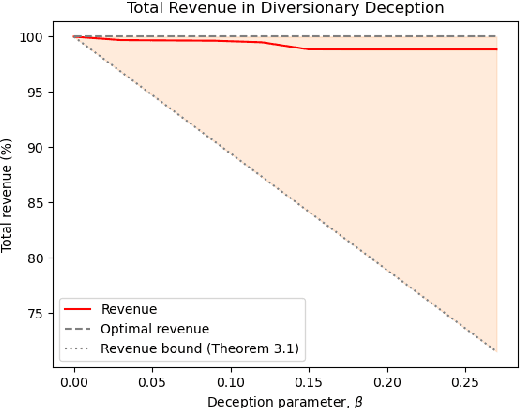
Autonomous systems are increasingly expected to operate in the presence of adversaries, though an adversary may infer sensitive information simply by observing a system, without even needing to interact with it. Therefore, in this work we present a deceptive decision-making framework that not only conceals sensitive information, but in fact actively misleads adversaries about it. We model autonomous systems as Markov decision processes, and we consider adversaries that attempt to infer their reward functions using inverse reinforcement learning. To counter such efforts, we present two regularization strategies for policy synthesis problems that actively deceive an adversary about a system's underlying rewards. The first form of deception is ``diversionary'', and it leads an adversary to draw any false conclusion about what the system's reward function is. The second form of deception is ``targeted'', and it leads an adversary to draw a specific false conclusion about what the system's reward function is. We then show how each form of deception can be implemented in policy optimization problems, and we analytically bound the loss in total accumulated reward that is induced by deception. Next, we evaluate these developments in a multi-agent sequential decision-making problem with one real agent and multiple decoys. We show that diversionary deception can cause the adversary to believe that the most important agent is the least important, while attaining a total accumulated reward that is $98.83\%$ of its optimal, non-deceptive value. Similarly, we show that targeted deception can make any decoy appear to be the most important agent, while still attaining a total accumulated reward that is $99.25\%$ of its optimal, non-deceptive value.