 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Distributed Second Order Optimization with Surrogate Sketching and Scaled Regularization
Paper and Code
Jul 02, 2020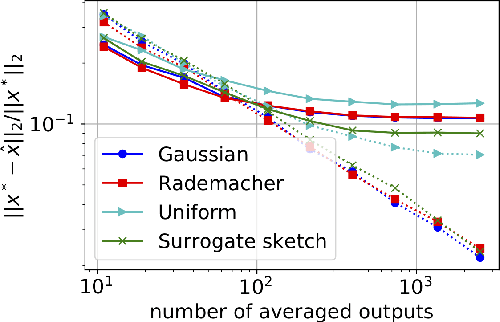

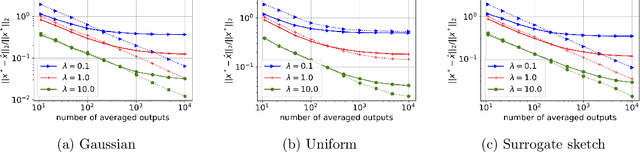
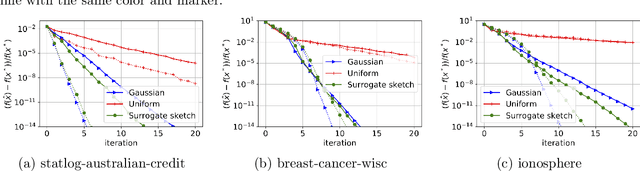
In distributed second order optimization, a standard strategy is to average many local estimates, each of which is based on a small sketch or batch of the data. However, the local estimates on each machine are typically biased, relative to the full solution on all of the data, and this can limit the effectiveness of averaging. Here, we introduce a new technique for debiasing the local estimates, which leads to both theoretical and empirical improvements in the convergence rate of distributed second order methods. Our technique has two novel components: (1) modifying standard sketching techniques to obtain what we call a surrogate sketch; and (2) carefully scaling the global regularization parameter for local computations. Our surrogate sketches are based on determinantal point processes, a family of distributions for which the bias of an estimate of the inverse Hessian can be computed exactly. Based on this computation, we show that when the objective being minimized is $l_2$-regularized with parameter $\lambda$ and individual machines are each given a sketch of size $m$, then to eliminate the bias, local estimates should be computed using a shrunk regularization parameter given by $\lambda^{\prime}=\lambda\cdot(1-\frac{d_{\lambda}}{m})$, where $d_{\lambda}$ is the $\lambda$-effective dimension of the Hessian (or, for quadratic problems, the data matrix).