 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-randomized PAC-Bayes Margin Bounds: Applications to Non-convex and Non-smooth Predictors
Paper and Code
Feb 23, 2020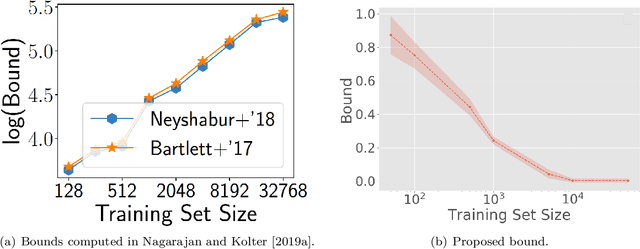
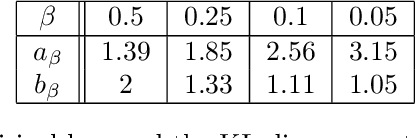
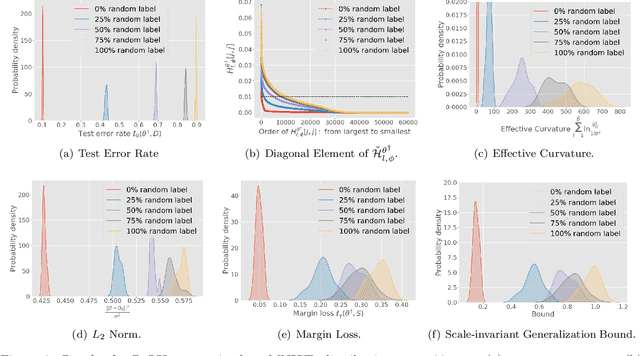
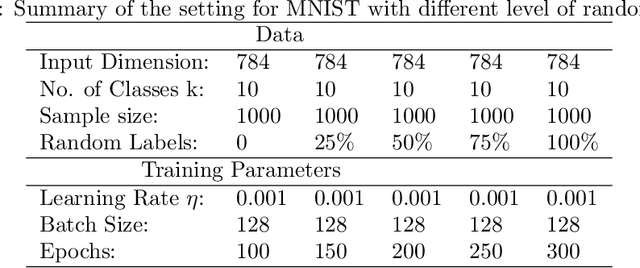
In spite of several notable efforts, explaining the generalization of deterministic deep nets, e.g., ReLU-nets, has remained challenging. Existing approaches usually need to bound the Lipschitz constant of such deep nets but such bounds have been shown to increase substantially with the number of training samples yielding vacuous generalization bounds [Nagarajan and Kolter, 2019a]. In this paper, we present new de-randomized PAC-Bayes margin bounds for deterministic non-convex and non-smooth predictors, e.g., ReLU-nets. The bounds depend on a trade-off between the $L_2$-norm of the weights and the effective curvature (`flatness') of the predictor, avoids any dependency on the Lipschitz constant, and yield meaningful (decreasing) bounds with increase in training set size. Our analysis first develops a de-randomization argument for non-convex but smooth predictors, e.g., linear deep networks (LDNs). We then consider non-smooth predictors which for any given input realize as a smooth predictor, e.g., ReLU-nets become some LDN for a given input, but the realized smooth predictor can be different for different inputs. For such non-smooth predictors, we introduce a new PAC-Bayes analysis that maintains distributions over the structure as well as parameters of smooth predictors, e.g., LDNs corresponding to ReLU-nets, which after de-randomization yields a bound for the deterministic non-smooth predictor. We present empirical results to illustrate the efficacy of our bounds over changing training set size and randomness in labels.