 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCFormer: Efficient 3D Vision-Language Modeling with Decomposed Convolutions
Paper and Code
Feb 07, 2025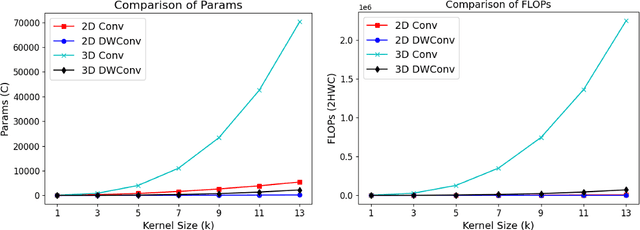



Vision-language models (VLMs) align visual and textual representations, enabling high-performance zero-shot classification and image-text retrieval in 2D medical imaging. However, extending VLMs to 3D medical imaging remains computationally challenging. Existing 3D VLMs rely on Vision Transformers (ViTs), which are computationally expensive due to self-attention's quadratic complexity, or 3D convolutions, which demand excessive parameters and FLOPs as kernel size increases. We introduce DCFormer, an efficient 3D medical image encoder that factorizes 3D convolutions into three parallel 1D convolutions along depth, height, and width. This design preserves spatial information while significantly reducing computational cost. Integrated into a CLIP-based vision-language framework, DCFormer is evaluated on CT-RATE, a dataset of 50,188 paired 3D chest CT volumes and radiology reports, for zero-shot multi-abnormality detection across 18 pathologies. Compared to ViT, ConvNeXt, PoolFormer, and TransUNet, DCFormer achieves superior efficiency and accuracy, with DCFormer-Tiny reaching 62.0% accuracy and a 46.3% F1-score while using significantly fewer parameters. These results highlight DCFormer's potential for scalable, clinically deployable 3D medical VLMs. Our codes will be publicly available.