 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Learning for Sim-to-Real Robotic Grasping using Deep Point Cloud Prediction Networks
Paper and Code
Jun 21, 2019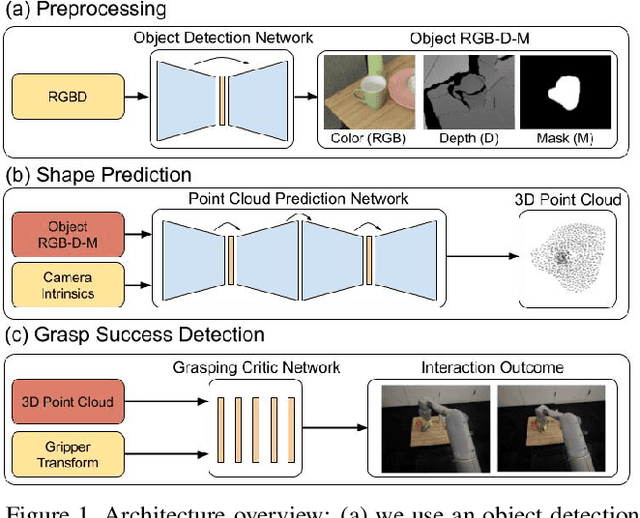
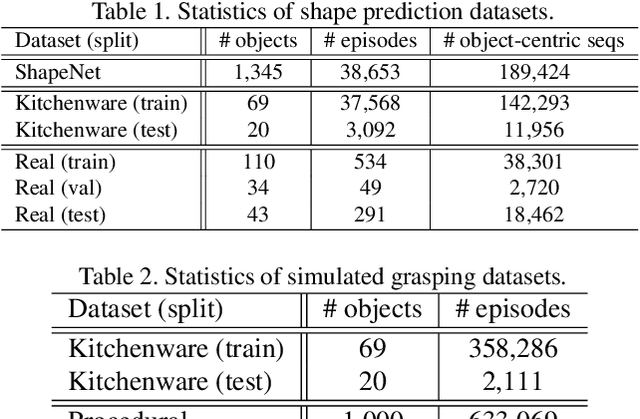
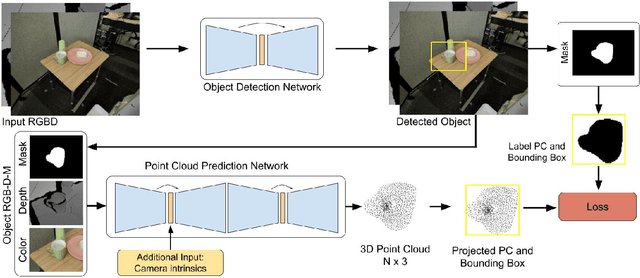
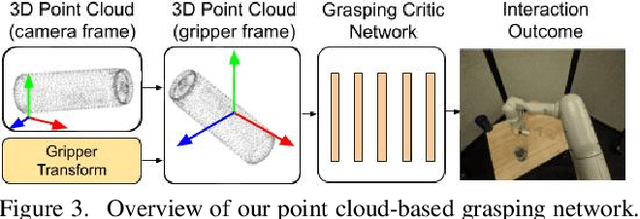
Training a deep network policy for robot manipulation is notoriously costly and time consuming as it depends on collecting a significant amount of real world data. To work well in the real world, the policy needs to see many instances of the task, including various object arrangements in the scene as well as variations in object geometry, texture, material, and environmental illumination. In this paper, we propose a method that learns to perform table-top instance grasping of a wide variety of objects while using no real world grasping data, outperforming the baseline using 2.5D shape by 10%. Our method learns 3D point cloud of object, and use that to train a domain-invariant grasping policy. We formulate the learning process as a two-step procedure: 1) Learning a domain-invariant 3D shape representation of objects from about 76K episodes in simulation and about 530 episodes in the real world, where each episode lasts less than a minute and 2) Learning a critic grasping policy in simulation only based on the 3D shape representation from step 1. Our real world data collection in step 1 is both cheaper and faster compared to existing approaches as it only requires taking multiple snapshots of the scene using a RGBD camera. Finally, the learned 3D representation is not specific to grasping, and can potentially be used in other interaction tasks.