 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Association Aware POMDP Planning with Hypothesis Pruning Performance Guarantees
Paper and Code
Mar 03, 2023
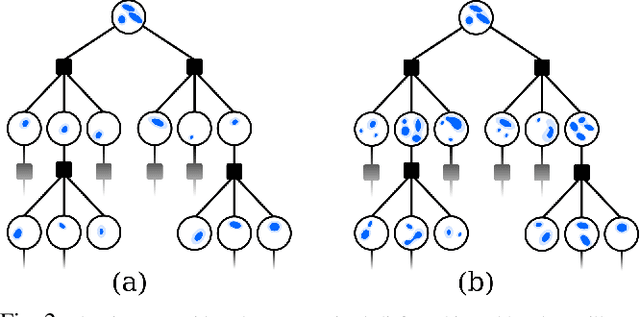
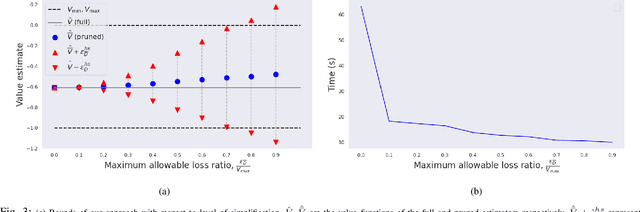

Autonomous agents that operate in the real world must often deal with partial observability, which is commonly modeled as partially observable Markov decision processes (POMDPs). However, traditional POMDP models rely on the assumption of complete knowledge of the observation source, known as fully observable data association. To address this limitation, we propose a planning algorithm that maintains multiple data association hypotheses, represented as a belief mixture, where each component corresponds to a different data association hypothesis. However, this method can lead to an exponential growth in the number of hypotheses, resulting in significant computational overhead. To overcome this challenge, we introduce a pruning-based approach for planning with ambiguous data associations. Our key contribution is to derive bounds between the value function based on the complete set of hypotheses and the value function based on a pruned-subset of the hypotheses, enabling us to establish a trade-off between computational efficiency and performance. We demonstrate how these bounds can both be used to certify any pruning heuristic in retrospect and propose a novel approach to determine which hypotheses to prune in order to ensure a predefined limit on the loss. We evaluate our approach in simulated environments and demonstrate its efficacy in handling multi-modal belief hypotheses with ambiguous data associations.