 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANCER: Entity Description Augmented Named Entity Corrector for Automatic Speech Recognition
Paper and Code
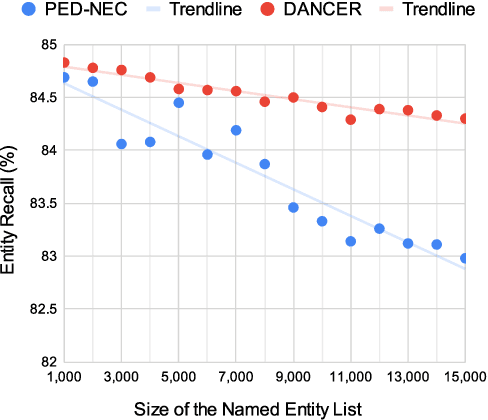
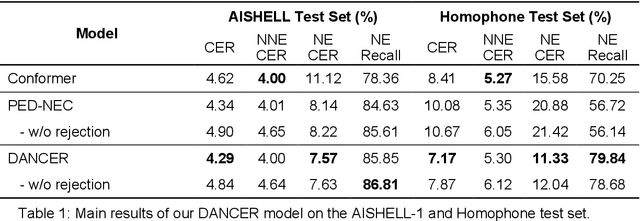
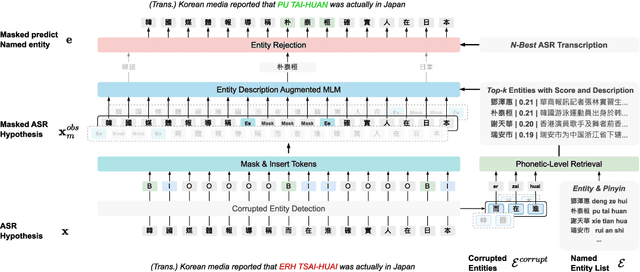
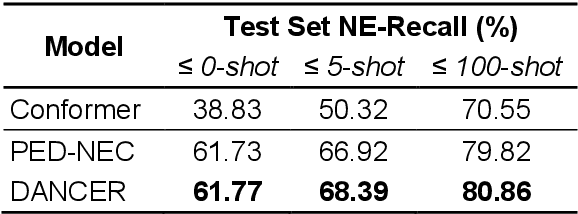
End-to-end automatic speech recognition (E2E ASR) systems often suffer from mistranscription of domain-specific phrases, such as named entities, sometimes leading to catastrophic failures in downstream tasks. A family of fast and lightweight named entity correction (NEC) models for ASR have recently been proposed, which normally build on phonetic-level edit distance algorithms and have shown impressive NEC performance. However, as the named entity (NE) list grows, the problems of phonetic confusion in the NE list are exacerbated; for example, homophone ambiguities increase substantially. In view of this, we proposed a novel Description Augmented Named entity CorrEctoR (dubbed DANCER), which leverages entity descriptions to provide additional information to facilitate mitigation of phonetic confusion for NEC on ASR transcription. To this end, an efficient entity description augmented masked language model (EDA-MLM) comprised of a dense retrieval model is introduced, enabling MLM to adapt swiftly to domain-specific entities for the NEC task. A series of experiments conducted on the AISHELL-1 and Homophone datasets confirm the effectiveness of our modeling approach. DANCER outperforms a strong baseline, the phonetic edit-distance-based NEC model (PED-NEC), by a character error rate (CER) reduction of about 7% relatively on AISHELL-1 for named entities. More notably, when tested on Homophone that contain named entities of high phonetic confusion, DANCER offers a more pronounced CER reduction of 46% relatively over PED-NEC for named entities.