 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANCE: DAta-Network Co-optimization for Efficient Segmentation Model Training and Inference
Paper and Code
Jul 16, 2021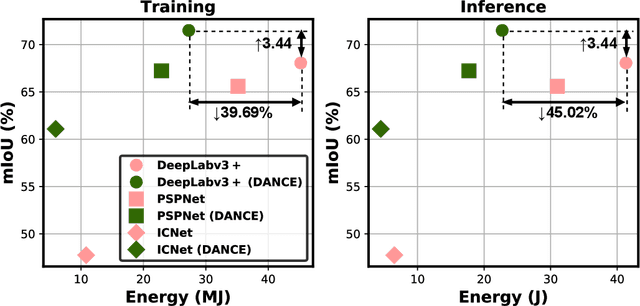



Semantic segmentation for scene understanding is nowadays widely demanded, raising significant challenges for the algorithm efficiency, especially its applications on resource-limited platforms. Current segmentation models are trained and evaluated on massive high-resolution scene images ("data level") and suffer from the expensive computation arising from the required multi-scale aggregation("network level"). In both folds, the computational and energy costs in training and inference are notable due to the often desired large input resolutions and heavy computational burden of segmentation models. To this end, we propose DANCE, general automated DAta-Network Co-optimization for Efficient segmentation model training and inference. Distinct from existing efficient segmentation approaches that focus merely on light-weight network design, DANCE distinguishes itself as an automated simultaneous data-network co-optimization via both input data manipulation and network architecture slimming. Specifically, DANCE integrates automated data slimming which adaptively downsamples/drops input images and controls their corresponding contribution to the training loss guided by the images' spatial complexity. Such a downsampling operation, in addition to slimming down the cost associated with the input size directly, also shrinks the dynamic range of input object and context scales, therefore motivating us to also adaptively slim the network to match the downsampled data. Extensive experiments and ablating studies (on four SOTA segmentation models with three popular segmentation datasets under two training settings) demonstrate that DANCE can achieve "all-win" towards efficient segmentation(reduced training cost, less expensive inference, and better mean Intersection-over-Union (mIoU)).