 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAGCN: Dual Attention Graph Convolutional Networks
Paper and Code
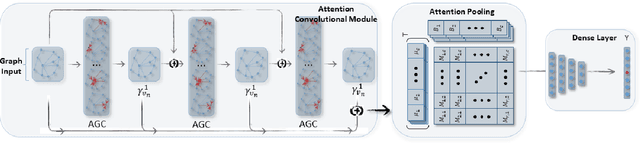
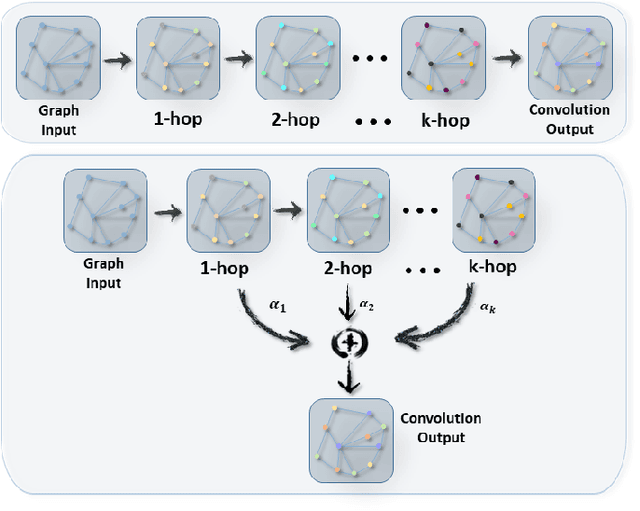
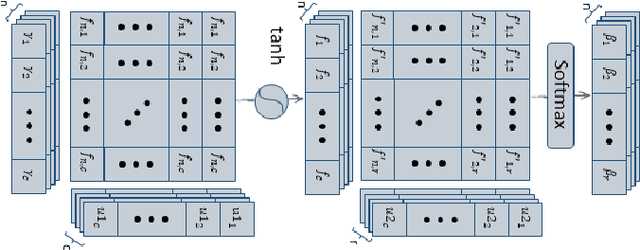
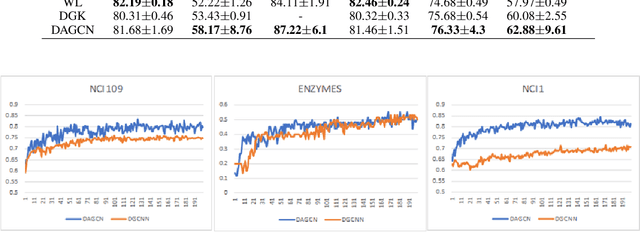
Graph convolutional networks (GCNs) have recently become one of the most powerful tools for graph analytics tasks in numerous applications, ranging from social networks and natural language processing to bioinformatics and chemoinformatics, thanks to their ability to capture the complex relationships between concepts. At present, the vast majority of GCNs use a neighborhood aggregation framework to learn a continuous and compact vector, then performing a pooling operation to generalize graph embedding for the classification task. These approaches have two disadvantages in the graph classification task: (1)when only the largest sub-graph structure ($k$-hop neighbor) is used for neighborhood aggregation, a large amount of early-stage information is lost during the graph convolution step; (2) simple average/sum pooling or max pooling utilized, which loses the characteristics of each node and the topology between nodes. In this paper, we propose a novel framework called, dual attention graph convolutional networks (DAGCN) to address these problems. DAGCN automatically learns the importance of neighbors at different hops using a novel attention graph convolution layer, and then employs a second attention component, a self-attention pooling layer, to generalize the graph representation from the various aspects of a matrix graph embedding. The dual attention network is trained in an end-to-end manner for the graph classification task. We compare our model with state-of-the-art graph kernels and other deep learning methods. The experimental results show that our framework not only outperforms other baselines but also achieves a better rate of convergence.