 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Labeling: Self-paced Pseudo-Labeling for Semi-Supervised Learning
Paper and Code

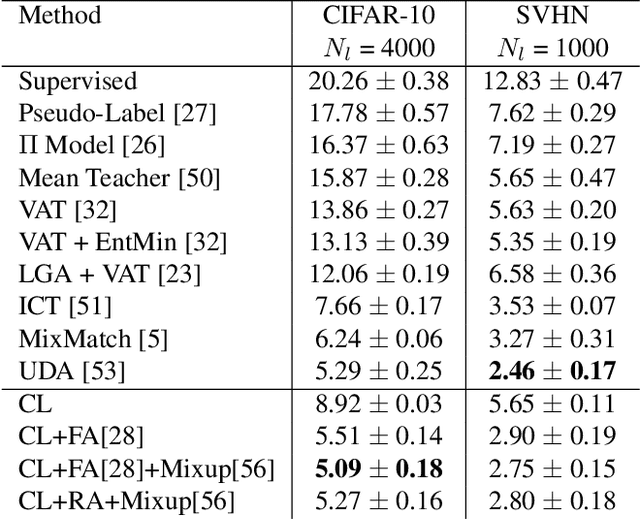
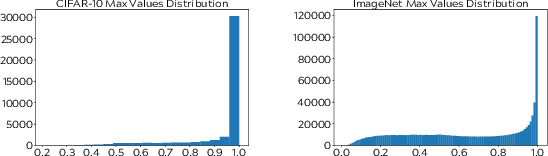
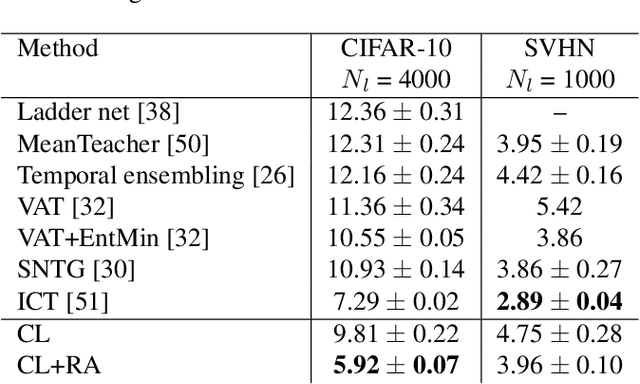
Semi-supervised learning aims to take advantage of a large amount of unlabeled data to improve the accuracy of a model that only has access to a small number of labeled examples. We propose curriculum labeling, an approach that exploits pseudo-labeling for propagating labels to unlabeled samples in an iterative and self-paced fashion. This approach is surprisingly simple and effective and surpasses or is comparable with the best methods proposed in the recent literature across all the standard benchmarks for image classification. Notably, we obtain 94.91% accuracy on CIFAR-10 using only 4,000 labeled samples, and 88.56% top-5 accuracy on Imagenet-ILSVRC using 128,000 labeled samples. In contrast to prior works, our approach shows improvements even in a more realistic scenario that leverages out-of-distribution unlabeled data samples.