 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUP: Cluster Pruning for Compressing Deep Neural Networks
Paper and Code
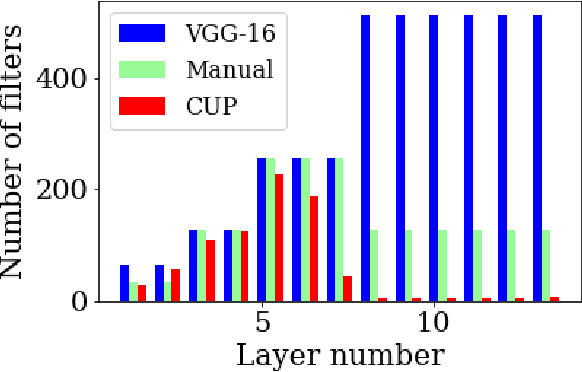
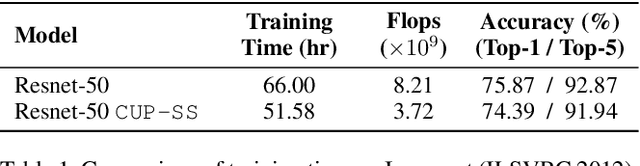
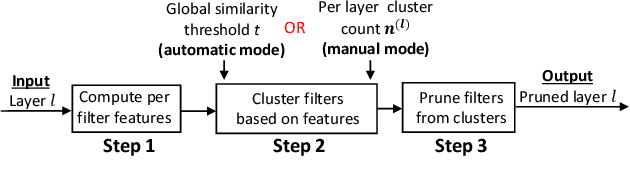
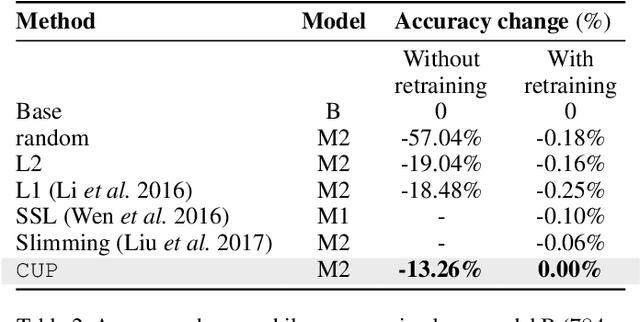
We propose Cluster Pruning (CUP) for compressing and accelerating deep neural networks. Our approach prunes similar filters by clustering them based on features derived from both the incoming and outgoing weight connections. With CUP, we overcome two limitations of prior work-(1) non-uniform pruning: CUP can efficiently determine the ideal number of filters to prune in each layer of a neural network. This is in contrast to prior methods that either prune all layers uniformly or otherwise use resource-intensive methods such as manual sensitivity analysis or reinforcement learning to determine the ideal number. (2) Single-shot operation: We extend CUP to CUP-SS (for CUP single shot) whereby pruning is integrated into the initial training phase itself. This leads to large savings in training time compared to traditional pruning pipelines. Through extensive evaluation on multiple datasets (MNIST, CIFAR-10, and Imagenet) and models(VGG-16, Resnets-18/34/56) we show that CUP outperforms recent state of the art. Specifically, CUP-SS achieves 2.2x flops reduction for a Resnet-50 model trained on Imagenet while staying within 0.9% top-5 accuracy. It saves over 14 hours in training time with respect to the original Resnet-50. The code to reproduce results is available.