Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCued@wmt19:ewc&lms
Paper and Code

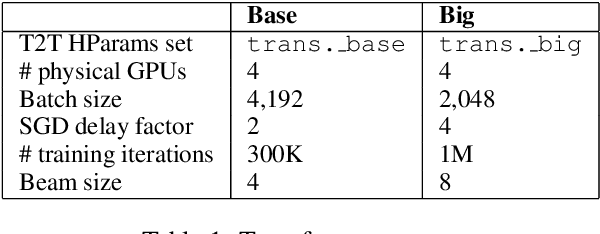
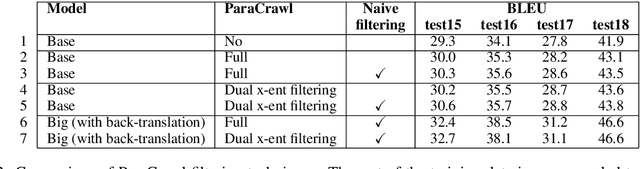
Two techniques provide the fabric of the Cambridge University Engineering Department's (CUED) entry to the WMT19 evaluation campaign: elastic weight consolidation (EWC) and different forms of language modelling (LMs). We report substantial gains by fine-tuning very strong baselines on former WMT test sets using a combination of checkpoint averaging and EWC. A sentence-level Transformer LM and a document-level LM based on a modified Transformer architecture yield further gains. As in previous years, we also extract $n$-gram probabilities from SMT lattices which can be seen as a source-conditioned $n$-gram LM.
* WMT2019 system description (University of Cambridge)
View paper on