 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossQuant: A Post-Training Quantization Method with Smaller Quantization Kernel for Precise Large Language Model Compression
Paper and Code
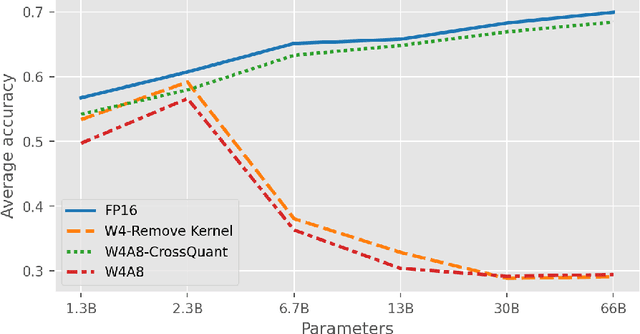

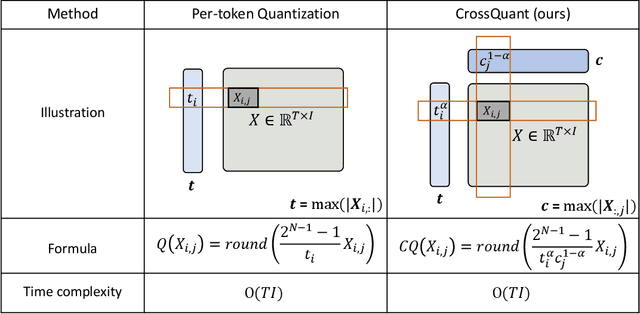

Post-Training Quantization (PTQ) is an effective technique for compressing Large Language Models (LLMs). While many studies focus on quantizing both weights and activations, it is still a challenge to maintain the accuracy of LLM after activating quantization. To investigate the primary cause, we extend the concept of kernel from linear algebra to quantization functions to define a new term, "quantization kernel", which refers to the set of elements in activations that are quantized to zero. Through quantitative analysis of the quantization kernel, we find that these elements are crucial for maintaining the accuracy of quantized LLMs. With the decrease of quantization kernel, the precision of quantized LLMs increases. If the quantization kernel proportion is kept below 19% for OPT models and below 1% for LLaMA models, the precision loss from quantizing activations to INT8 becomes negligible. Motivated by the goal of developing a quantization method with small quantization kernel, we propose CrossQuant: a simple yet effective method for quantizing activations. CrossQuant cross-quantizes elements using row and column-wise absolute maximum vectors, achieving a quantization kernel of approximately 16% for OPT models and less than 0.1% for LLaMA models. Experimental results on LLMs (LLaMA, OPT) ranging from 6.7B to 70B parameters demonstrate that CrossQuant improves or maintains perplexity and accuracy in language modeling, zero-shot, and few-shot tasks.