 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossing Generative Adversarial Networks for Cross-View Person Re-identification
Paper and Code
Jan 04, 2018

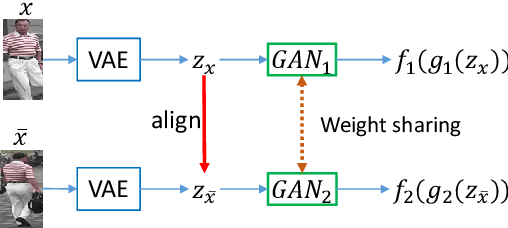

Person re-identification (\textit{re-id}) refers to matching pedestrians across disjoint yet non-overlapping camera views. The most effective way to match these pedestrians undertaking significant visual variations is to seek reliably invariant features that can describe the person of interest faithfully. Most of existing methods are presented in a supervised manner to produce discriminative features by relying on labeled paired images in correspondence. However, annotating pair-wise images is prohibitively expensive in labors, and thus not practical in large-scale networked cameras. Moreover, seeking comparable representations across camera views demands a flexible model to address the complex distributions of images. In this work, we study the co-occurrence statistic patterns between pairs of images, and propose to crossing Generative Adversarial Network (Cross-GAN) for learning a joint distribution for cross-image representations in a unsupervised manner. Given a pair of person images, the proposed model consists of the variational auto-encoder to encode the pair into respective latent variables, a proposed cross-view alignment to reduce the view disparity, and an adversarial layer to seek the joint distribution of latent representations. The learned latent representations are well-aligned to reflect the co-occurrence patterns of paired images. We empirically evaluate the proposed model against challenging datasets, and our results show the importance of joint invariant features in improving matching rates of person re-id with comparison to semi/unsupervised state-of-the-arts.