 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Constituency Parsing for Middle High German: A Delexicalized Approach
Paper and Code
Aug 29, 2023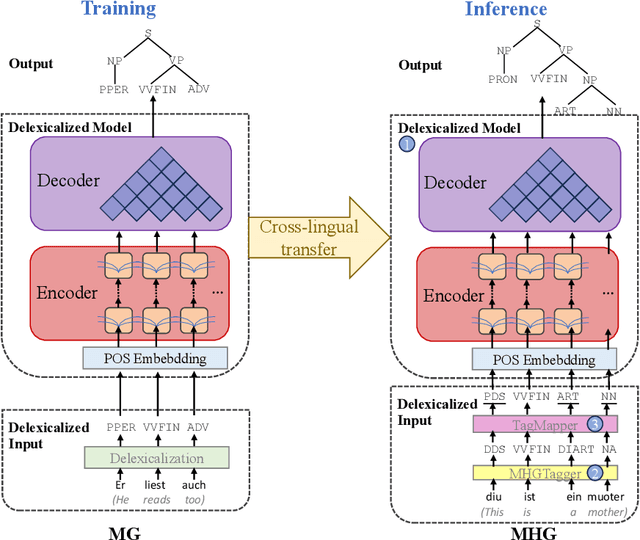



Constituency parsing plays a fundamental role in advancing natural language processing (NLP) tasks. However, training an automatic syntactic analysis system for ancient languages solely relying on annotated parse data is a formidable task due to the inherent challenges in building treebanks for such languages. It demands extensive linguistic expertise, leading to a scarcity of available resources. To overcome this hurdle, cross-lingual transfer techniques which require minimal or even no annotated data for low-resource target languages offer a promising solution. In this study, we focus on building a constituency parser for $\mathbf{M}$iddle $\mathbf{H}$igh $\mathbf{G}$erman ($\mathbf{MHG}$) under realistic conditions, where no annotated MHG treebank is available for training. In our approach, we leverage the linguistic continuity and structural similarity between MHG and $\mathbf{M}$odern $\mathbf{G}$erman ($\mathbf{MG}$), along with the abundance of MG treebank resources. Specifically, by employing the $\mathit{delexicalization}$ method, we train a constituency parser on MG parse datasets and perform cross-lingual transfer to MHG parsing. Our delexicalized constituency parser demonstrates remarkable performance on the MHG test set, achieving an F1-score of 67.3%. It outperforms the best zero-shot cross-lingual baseline by a margin of 28.6% points. These encouraging results underscore the practicality and potential for automatic syntactic analysis in other ancient languages that face similar challenges as MHG.