 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPGAN: Full-Spectrum Content-Parsing Generative Adversarial Networks for Text-to-Image Synthesis
Paper and Code
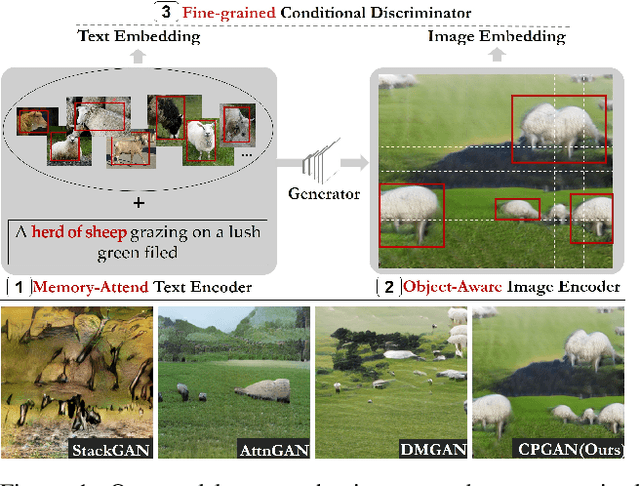

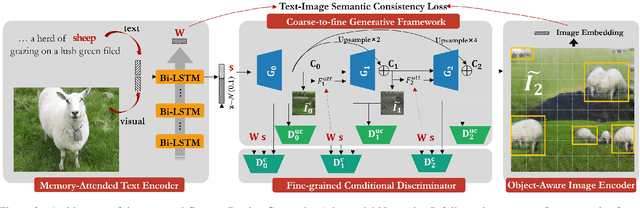
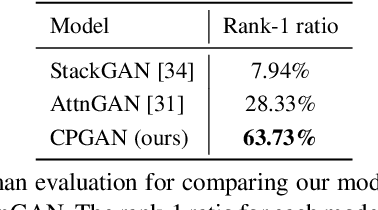
Typical methods for text-to-image synthesis seek to design effective generative architecture to model the text-to-image mapping directly. It is fairly arduous due to the cross-modality translation involved in the task of text-to-image synthesis. In this paper we circumvent this problem by focusing on parsing the content of both the input text and the synthesized image thoroughly to model the text-to-image consistency in the semantic level. In particular, we design a memory structure to parse the textual content by exploring semantic correspondence between each word in the vocabulary to its various visual contexts across relevant images in training data during text encoding. On the other hand, the synthesized image is parsed to learn its semantics in an object-aware manner. Moreover, we customize a conditional discriminator, which models the fine-grained correlations between words and image sub-regions to push for the cross-modality semantic alignment between the input text and the synthesized image. Thus, a full-spectrum content-oriented parsing in the deep semantic level is performed by our model, which is referred to as Content-Parsing Generative Adversarial Networks (CPGAN). Extensive experiments on COCO dataset manifest that CPGAN advances the state-of-the-art performance significantly.