 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountering Language Drift with Seeded Iterated Learning
Paper and Code
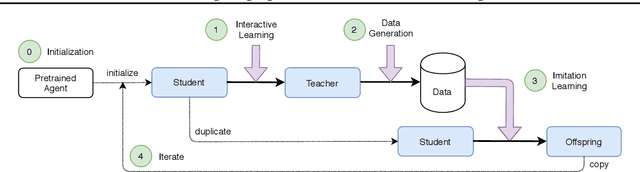

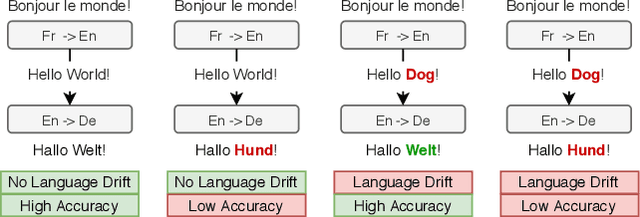
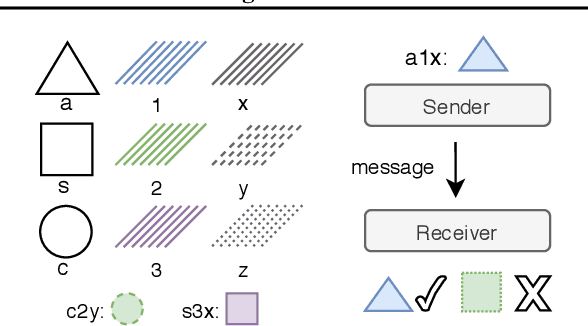
Supervised learning methods excel at capturing statistical properties of language when trained over large text corpora. Yet, these models often produce inconsistent outputs in goal-oriented language settings as they are not trained to complete the underlying task. Moreover, as soon as the agents are finetuned to maximize task completion, they suffer from the so-called language drift phenomenon: they slowly lose syntactic and semantic properties of language as they only focus on solving the task. In this paper, we propose a generic approach to counter language drift by using iterated learning. We iterate between fine-tuning agents with interactive training steps, and periodically replacing them with new agents that are seeded from last iteration and trained to imitate the latest finetuned models. Iterated learning does not require external syntactic constraint nor semantic knowledge, making it a valuable task-agnostic finetuning protocol. We first explore iterated learning in the Lewis Game. We then scale-up the approach in the translation game. In both settings, our results show that iterated learn-ing drastically counters language drift as well as it improves the task completion metric.