 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Variable Control for Robust and Interpretable Question Answering
Paper and Code
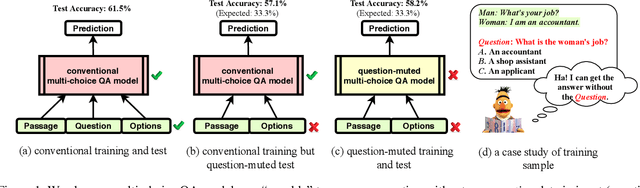



Deep neural network based question answering (QA) models are neither robust nor explainable in many cases. For example, a multiple-choice QA model, tested without any input of question, is surprisingly "capable" to predict the most of correct options. In this paper, we inspect such spurious "capability" of QA models using causal inference. We find the crux is the shortcut correlation, e.g., unrobust word alignment between passage and options learned by the models. We propose a novel approach called Counterfactual Variable Control (CVC) that explicitly mitigates any shortcut correlation and preserves the comprehensive reasoning for robust QA. Specifically, we leverage multi-branch architecture that allows us to disentangle robust and shortcut correlations in the training process of QA. We then conduct two novel CVC inference methods (on trained models) to capture the effect of comprehensive reasoning as the final prediction. For evaluation, we conduct extensive experiments using two BERT backbones on both multi-choice and span-extraction QA benchmarks. The results show that our CVC achieves high robustness against a variety of adversarial attacks in QA while maintaining good interpretation ability.