 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Effective Training in Low-Resource Neural Machine Translation
Paper and Code
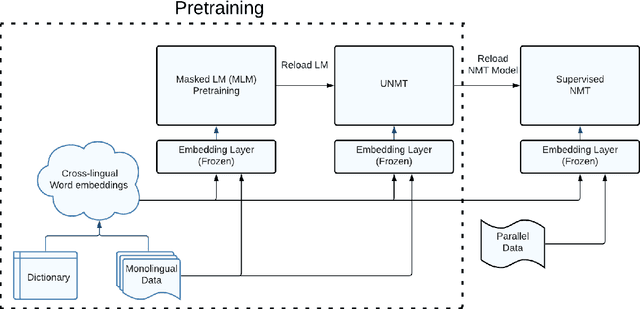

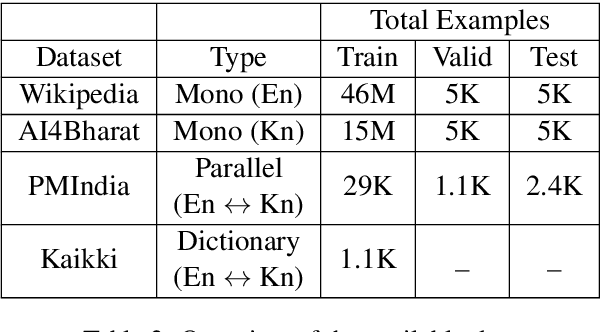
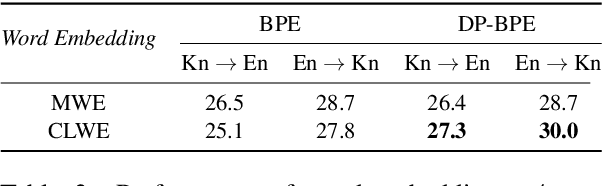
While Active Learning (AL) techniques are explored in Neural Machine Translation (NMT), only a few works focus on tackling low annotation budgets where a limited number of sentences can get translated. Such situations are especially challenging and can occur for endangered languages with few human annotators or having cost constraints to label large amounts of data. Although AL is shown to be helpful with large budgets, it is not enough to build high-quality translation systems in these low-resource conditions. In this work, we propose a cost-effective training procedure to increase the performance of NMT models utilizing a small number of annotated sentences and dictionary entries. Our method leverages monolingual data with self-supervised objectives and a small-scale, inexpensive dictionary for additional supervision to initialize the NMT model before applying AL. We show that improving the model using a combination of these knowledge sources is essential to exploit AL strategies and increase gains in low-resource conditions. We also present a novel AL strategy inspired by domain adaptation for NMT and show that it is effective for low budgets. We propose a new hybrid data-driven approach, which samples sentences that are diverse from the labelled data and also most similar to unlabelled data. Finally, we show that initializing the NMT model and further using our AL strategy can achieve gains of up to $13$ BLEU compared to conventional AL methods.