 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrespondence Analysis Using Neural Networks
Paper and Code
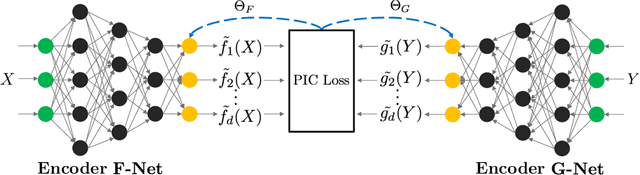

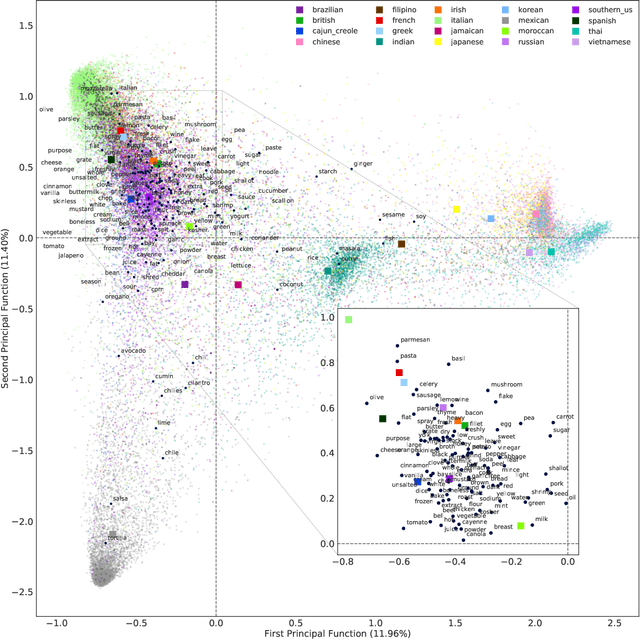
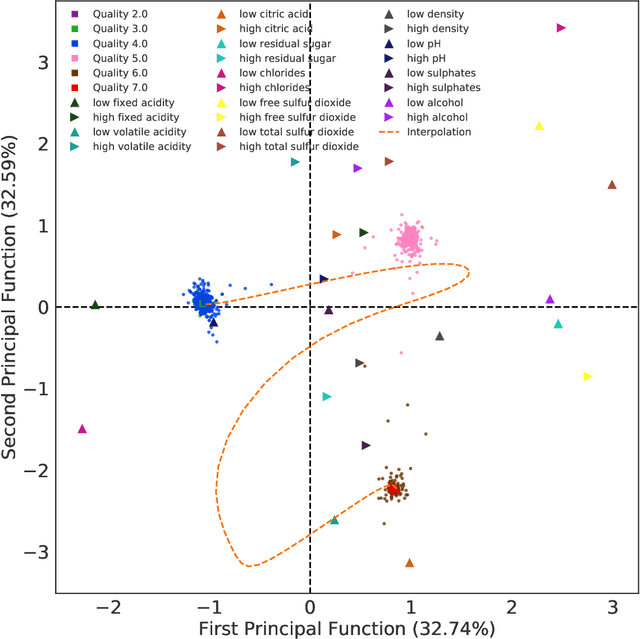
Correspondence analysis (CA) is a multivariate statistical tool used to visualize and interpret data dependencies. CA has found applications in fields ranging from epidemiology to social sciences. However, current methods used to perform CA do not scale to large, high-dimensional datasets. By re-interpreting the objective in CA using an information-theoretic tool called the principal inertia components, we demonstrate that performing CA is equivalent to solving a functional optimization problem over the space of finite variance functions of two random variable. We show that this optimization problem, in turn, can be efficiently approximated by neural networks. The resulting formulation, called the correspondence analysis neural network (CA-NN), enables CA to be performed at an unprecedented scale. We validate the CA-NN on synthetic data, and demonstrate how it can be used to perform CA on a variety of datasets, including food recipes, wine compositions, and images. Our results outperform traditional methods used in CA, indicating that CA-NN can serve as a new, scalable tool for interpretability and visualization of complex dependencies between random variables.