 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation Pyramid Network for 3D Single Object Tracking
Paper and Code
May 16, 2023

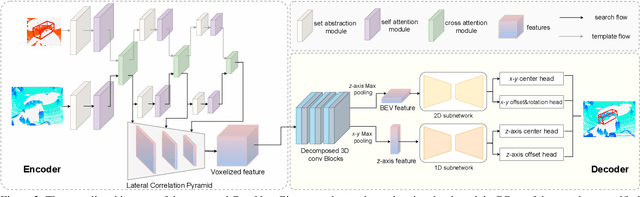
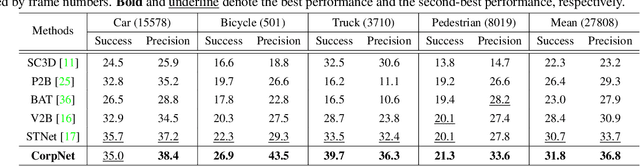
3D LiDAR-based single object tracking (SOT) has gained increasing attention as it plays a crucial role in 3D applications such as autonomous driving. The central problem is how to learn a target-aware representation from the sparse and incomplete point clouds. In this paper, we propose a novel Correlation Pyramid Network (CorpNet) with a unified encoder and a motion-factorized decoder. Specifically, the encoder introduces multi-level self attentions and cross attentions in its main branch to enrich the template and search region features and realize their fusion and interaction, respectively. Additionally, considering the sparsity characteristics of the point clouds, we design a lateral correlation pyramid structure for the encoder to keep as many points as possible by integrating hierarchical correlated features. The output features of the search region from the encoder can be directly fed into the decoder for predicting target locations without any extra matcher. Moreover, in the decoder of CorpNet, we design a motion-factorized head to explicitly learn the different movement patterns of the up axis and the x-y plane together. Extensive experiments on two commonly-used datasets show our CorpNet achieves state-of-the-art results while running in real-time.