 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoresets for Time Series Clustering
Paper and Code
Oct 28, 2021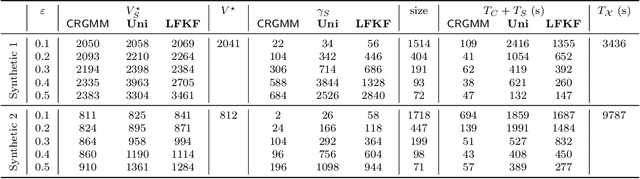
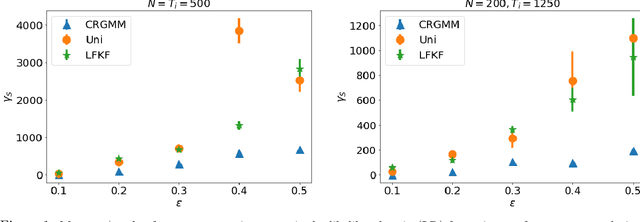
We study the problem of constructing coresets for clustering problems with time series data. This problem has gained importance across many fields including biology, medicine, and economics due to the proliferation of sensors facilitating real-time measurement and rapid drop in storage costs. In particular, we consider the setting where the time series data on $N$ entities is generated from a Gaussian mixture model with autocorrelations over $k$ clusters in $\mathbb{R}^d$. Our main contribution is an algorithm to construct coresets for the maximum likelihood objective for this mixture model. Our algorithm is efficient, and under a mild boundedness assumption on the covariance matrices of the underlying Gaussians, the size of the coreset is independent of the number of entities $N$ and the number of observations for each entity, and depends only polynomially on $k$, $d$ and $1/\varepsilon$, where $\varepsilon$ is the error parameter. We empirically assess the performance of our coreset with synthetic data.