 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoresets for Regressions with Panel Data
Paper and Code
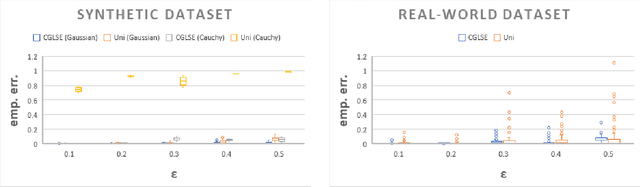
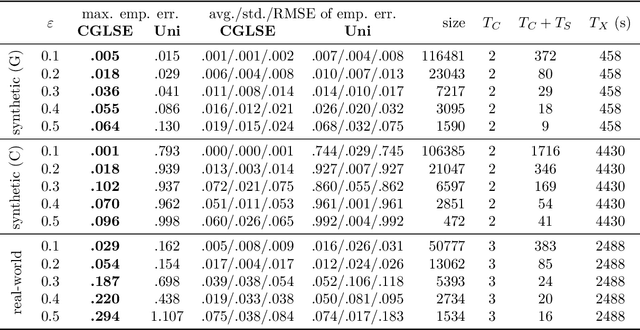
This paper introduces the problem of coresets for regression problems to panel data settings. We first define coresets for several variants of regression problems with panel data and then present efficient algorithms to construct coresets of size that depend polynomially on 1/$\varepsilon$ (where $\varepsilon$ is the error parameter) and the number of regression parameters - independent of the number of individuals in the panel data or the time units each individual is observed for. Our approach is based on the Feldman-Langberg framework in which a key step is to upper bound the "total sensitivity" that is roughly the sum of maximum influences of all individual-time pairs taken over all possible choices of regression parameters. Empirically, we assess our approach with synthetic and real-world datasets; the coreset sizes constructed using our approach are much smaller than the full dataset and coresets indeed accelerate the running time of computing the regression objective.