 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Risk Minimization and Conditional Probability Estimation
Paper and Code
Jun 15, 2015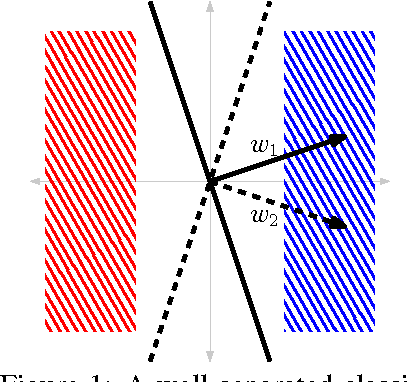
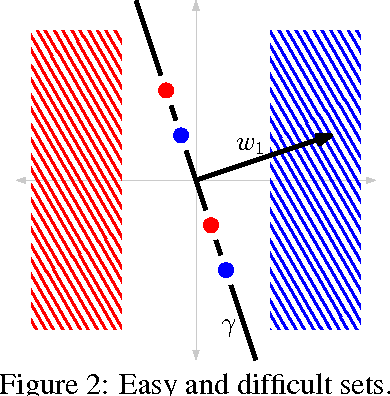
This paper proves, in very general settings, that convex risk minimization is a procedure to select a unique conditional probability model determined by the classification problem. Unlike most previous work, we give results that are general enough to include cases in which no minimum exists, as occurs typically, for instance, with standard boosting algorithms. Concretely, we first show that any sequence of predictors minimizing convex risk over the source distribution will converge to this unique model when the class of predictors is linear (but potentially of infinite dimension). Secondly, we show the same result holds for \emph{empirical} risk minimization whenever this class of predictors is finite dimensional, where the essential technical contribution is a norm-free generalization bound.