 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence and Stability of the Stochastic Proximal Point Algorithm with Momentum
Paper and Code
Dec 03, 2021


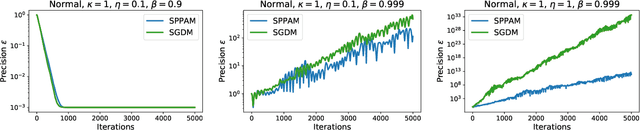
Stochastic gradient descent with momentum (SGDM) is the dominant algorithm in many optimization scenarios, including convex optimization instances and non-convex neural network training. Yet, in the stochastic setting, momentum interferes with gradient noise, often leading to specific step size and momentum choices in order to guarantee convergence, set aside acceleration. Proximal point methods, on the other hand, have gained much attention due to their numerical stability and elasticity against imperfect tuning. Their stochastic accelerated variants though have received limited attention: how momentum interacts with the stability of (stochastic) proximal point methods remains largely unstudied. To address this, we focus on the convergence and stability of the stochastic proximal point algorithm with momentum (SPPAM), and show that SPPAM allows a faster linear convergence rate compared to stochastic proximal point algorithm (SPPA) with a better contraction factor, under proper hyperparameter tuning. In terms of stability, we show that SPPAM depends on problem constants more favorably than SGDM, allowing a wider range of step size and momentum that lead to convergence.