 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Augmentations for Video Representation Learning
Paper and Code
Apr 01, 2022

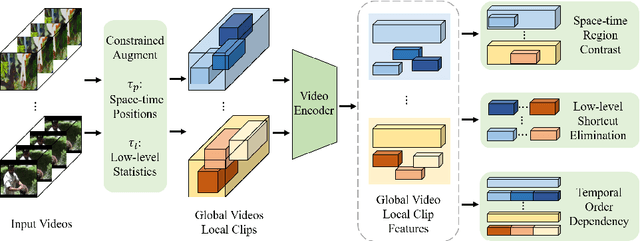

This paper focuses on self-supervised video representation learning. Most existing approaches follow the contrastive learning pipeline to construct positive and negative pairs by sampling different clips. However, this formulation tends to bias to static background and have difficulty establishing global temporal structures. The major reason is that the positive pairs, i.e., different clips sampled from the same video, have limited temporal receptive field, and usually share similar background but differ in motions. To address these problems, we propose a framework to jointly utilize local clips and global videos to learn from detailed region-level correspondence as well as general long-term temporal relations. Based on a set of controllable augmentations, we achieve accurate appearance and motion pattern alignment through soft spatio-temporal region contrast. Our formulation is able to avoid the low-level redundancy shortcut by mutual information minimization to improve the generalization. We also introduce local-global temporal order dependency to further bridge the gap between clip-level and video-level representations for robust temporal modeling. Extensive experiments demonstrate that our framework is superior on three video benchmarks in action recognition and video retrieval, capturing more accurate temporal dynamics.